Fair AI: Performance That Leaves No One Behind
Why neutral models default to biased outcomes—and how to engineer equity into AI systems
There's a persistent myth that because data is just data, machine learning models are inherently objective. But AI learns from a biased world, and neutral models often default to biased outcomes.
Consider retinal imaging: a patient's skin pigmentation directly impacts the appearance of the fundus image. A model that doesn't account for this biological variation isn't neutral—it's simply more likely to produce lower-quality results for certain racial groups. Similarly, models trained on Electronic Health Record data are naturally biased toward populations with consistent healthcare access, effectively making those who lack primary care invisible to the system.
Fairness in impactful AI means performance that is consistent, appropriate, and justifiable across all relevant populations. The core question isn't whether your model is accurate—it's identifying who is experiencing model instability. When older patients' brains change with age or accumulated strokes, accuracy can decrease in that specific demographic. When pulse oximeters provide inaccurate readings for patients with darker skin tones, a technical error becomes a profound fairness issue based on who it affects.
No technology can truly be impactful if it leaves specific populations behind or worsens existing inequities.
Why AI Fails the Fairness Test
Bias is rarely the result of malicious intent. It's typically a systemic failure within data and engineering pipelines. Because machine learning models are designed to find and replicate patterns, they naturally inherit and amplify the inequities present in historical records, human subjectivity, and technical limitations.
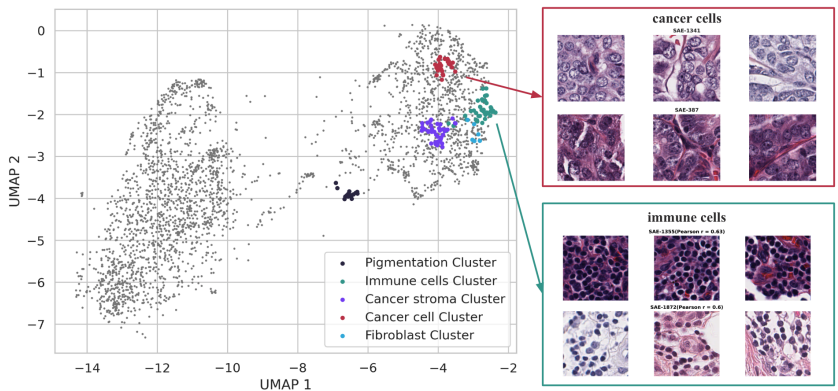
Representation bias occurs when specific groups are under-represented. Clinical datasets are often under-powered for Asian women—a group representing a large portion of global breast cancer patients but a minority in US-based research.
Sampling and access bias reflects only those who can afford or access elite care. Consumer fitness devices primarily collect data from healthy populations, which is often inappropriate for models intended to treat patients with chronic diseases.
Measurement and technical bias occurs when hardware performs inconsistently across populations. Skin pigmentation changes the appearance of an eye's fundus, meaning a sensor calibrated for one racial group may produce lower-quality data for another.
Label and annotation bias stems from human subjectivity. Inter-reviewer agreement for labeling EEG data can be surprisingly low, and experts frequently disagree on tissue boundaries or cell classifications. The AI is often learning from an inconsistent ground truth.
There Is No Single Fairness Button
Building an equitable system requires choosing the specific definition of fairness that aligns with your clinical or industrial objective.
Demographic parity ensures final outcomes are distributed equally across groups—every patient receives consistent diagnostic quality regardless of background.
Equal opportunity focuses on ensuring true positive rates are the same for everyone, so no group suffers higher rates of missed detections. This means validating that cancer detection models achieve comparable predictive power across racial groups.
Predictive parity ensures a high-risk score represents the same likelihood of disease for all subgroups—including variables like patient age and tissue density.
Individual fairness asks whether two similar individuals receive the same treatment regardless of group membership. A single patient imaged on different devices should receive the same calibrated risk score.
And underlying all of these is an honest acknowledgment of tradeoff reality: the balance between sensitivity and specificity is a deliberate human decision based on the cost of failure.
Engineering Fairness Into the System
Impactful teams don't treat fairness as an external audit—they weave it into data, architecture, and deployment from day one.
At the data level, this means purposefully engineering training data to reflect real-world diversity. When regulators identify dataset skew toward one scanner manufacturer, proactive teams acquire additional data to ensure hardware-agnostic performance. Ethical frameworks must dictate data collection from the beginning rather than checking for fairness after the model is built.
At the model level, architectures can be engineered to ignore irrelevant or biased signals. Preprocessing can suppress shortcut signals—like font styles from different scanner manufacturers—that might lead a model to predict disease based on hospital prevalence rather than biology. Self-supervised learning can be inherently more resilient to bias because it learns from raw data rather than human-provided labels carrying annotator prejudices.
At validation, impactful AI replaces average accuracy with rigorous performance requirements across every protected class. This means stratified benchmarks sliced by gender, age, and other demographic variables—proving precision for each subgroup before deployment.
At deployment, models run in shadow mode before impacting decisions, ensuring calibration to a new facility's unique data distribution. Quality assurance systems catch unpredictable behavior before it causes harm.
The Business Case for Fairness
Beyond ethics, fairness is a fundamental business requirement for global scale. A model performing well only on a population subset is effectively a niche product. A fair, robust system can capture 100% of the market.
In high-stakes sectors like medicine, proving fairness is increasingly a regulatory requirement. FDA clearance now demands proof that models perform consistently across age brackets, genders, and hardware manufacturers. Regulators serve as a forcing function—requiring balanced datasets when they identify manufacturer bias.
The cost of deploying a biased system extends beyond legal exposure to erosion of institutional trust. While a human error is often viewed as an accident, an algorithmic error is seen as systematic bias—making any failure completely unacceptable to the public.
A technology cannot claim to have revolutionized a field if its benefits are restricted by geography, wealth, or ethnicity. True impact isn't a statistical average across a privileged cohort—it's consistent delivery of high-quality outcomes for every individual.
But fairness cannot be taken on faith. To trust that a model acts equitably, we must examine its internal logic—ensuring it reaches results through legitimate signals rather than hidden shortcuts or biased proxies. This brings me to the next pillar: to verify fairness, we need transparency. We cannot claim a system is just if we cannot see how it makes its decisions. Stay tuned for the next newsletter focusing on transparency.
- Heather
|