Prediction ≠ Decision: Why AI Needs Oversight
AI systems are powerful pattern recognizers. They can predict with remarkable accuracy whether a satellite image contains smoke, whether a pathology slide contains tumor cells, or whether a field of crops shows signs of stress.
But here’s the trap: prediction is not the same as decision.
Too many AI projects fail because leaders expect models to replace reasoning, context, and judgment. In reality, predictions are inputs — valuable, yes, but incomplete. Decisions require oversight.
When Prediction Falls Short
Medicine: A model may predict the likelihood of cancer on a histology slide. But only a pathologist — with clinical history, other tests, and years of experience — can decide on a diagnosis and treatment.
Earth observation: A vision model may label a region as “deforestation.” But deciding whether that represents illegal logging, seasonal clearing, or land conversion requires local context and policy judgment.
Agriculture: Drone imagery might predict crop stress. But deciding whether to irrigate, fertilize, or replant depends on economics, supply chain timing, and farmer expertise.
Conservation: A computer vision model might predict species counts from camera trap images. But deciding whether a population is stable, threatened, or requires intervention involves ecological expertise, policy considerations, and on-the-ground validation.
In each case, mistaking prediction for decision is a costly shortcut.
This is why oversight matters.
Why Oversight Matters
Predictions are probabilistic. They’re shaped by the data a model sees — and by the biases, blind spots, and shortcuts it learns along the way.
Decisions, in contrast, carry consequences. They involve trade-offs, accountability, and integration with broader systems.
Without oversight, AI systems risk:
Overconfidence in spurious patterns (creating a false sense of certainty that the model is always right).
Failure under distribution shift (new labs, sensors, or geographies).
Misalignment with business or scientific goals.
Loss of trust from users, customers, and regulators.
The Leader’s Responsibility
Leaders don’t need to know the intricacies of model architecture. But they do need to set the right frame:
Treat predictions as decision support. Vision AI augments human expertise — it doesn’t replace it.
Build oversight into every stage. Data oversight ensures training and validation data reflect the real world. Model oversight checks that predictions generalize and avoid shortcuts. Workflow oversight guarantees that outputs fit into human decision processes safely.
Validate against the real decision context. Don’t just test model accuracy. Test whether the system improves the decisions that matter.
Link outputs to ROI. The measure of success isn’t accuracy — it’s avoided costs, reduced delays, and improved outcomes.
Why This Matters Now
As organizations scale up the use of computer vision, the temptation is to delegate more and more responsibility to algorithms. But the last mile of AI impact isn’t about bigger models. It’s about smarter oversight.
The projects that thrive are the ones that pair strong predictions with even stronger oversight. Which side is your team investing in?
- Heather
|

|
Closing the Last-Mile Gap in Vision AI for People, Planet, and Science
|
|
|
|
|
|
 |
Blog: Foundation Models for Pathology
How Foundation Models Are Revolutionizing Pathology AI
Pathology AI is evolving—fast. Are you keeping up?
Most histology models still break down outside the lab. But a new generation of foundation models—trained on massive H&E datasets—are changing how we build, validate, and deploy AI for pathology.
Instead of training from scratch, you can now:
✅ Prototype with just 100 slides
✅ Tackle weak supervision with ease
✅ Improve robustness across scanners and labs
✅ Explore slide-level and multimodal models
I published an article that breaks it all down:
👉 How Foundation Models Are Revolutionizing Pathology AI
You’ll find:
🔍 Practical use cases
🧪 4 ways to use foundation models (no GPU farm required)
📊 Tips
for choosing the right model for your task
🧠 A free 30-minute webinar replay to go deeper
If you’re building pathology AI—or thinking about it—this will help you skip the painful learning curve.
|
|
|
|
|
|
 |
Research: Foundation Model for EO
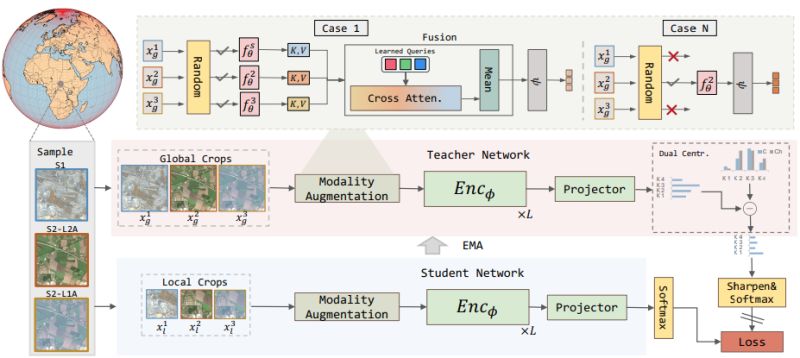
TerraFM: A Scalable Foundation Model for Unified Multisensor Earth Observation
Current EO models face a fundamental limitation: they're often designed for single sensor types, missing the complementary information available when combining radar and optical data. This fragmentation means we can't fully leverage the wealth of satellite observations monitoring our planet.
Danish et al. introduced TerraFM, a foundation model that unifies multisensor Earth observation in an unprecedented way.
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬:
Earth observation data comes from diverse sensors—optical imagery captures surface details but is limited by clouds and darkness, while SAR radar penetrates clouds and works day-night but
provides different information types. Many current models handle these separately, but the real world requires integrated understanding. Climate monitoring, disaster response, and agricultural assessment all benefit from fusing these complementary data streams.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
◦ 𝐌𝐚𝐬𝐬𝐢𝐯𝐞 𝐬𝐜𝐚𝐥𝐞 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠: Built on 18.7M global tiles from Sentinel-1 SAR and Sentinel-2 optical imagery, providing unprecedented geographic and spectral diversity
◦ 𝐋𝐚𝐫𝐠𝐞 𝐬𝐩𝐚𝐭𝐢𝐚𝐥 𝐭𝐢𝐥𝐞𝐬: Uses 534×534 pixel tiles to capture broader spatial context compared to traditional
smaller patches, enabling better understanding of landscape-scale patterns
◦ 𝐌𝐨𝐝𝐚𝐥𝐢𝐭𝐲-𝐚𝐰𝐚𝐫𝐞 𝐚𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞: Modality-specific patch embeddings handle the unique characteristics of multispectral and SAR data rather than forcing them through RGB-centric designs
◦ 𝐂𝐫𝐨𝐬𝐬-𝐚𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧 𝐟𝐮𝐬𝐢𝐨𝐧: Dynamically aggregates information across sensors at the patch level, learning how different modalities complement each other
◦ 𝐃𝐮𝐚𝐥-𝐜𝐞𝐧𝐭𝐞𝐫𝐢𝐧𝐠: Addresses the long-tailed distribution problem in land cover data using
ESA WorldCover statistics, ensuring rare classes aren't overshadowed
𝐓𝐡𝐞 𝐫𝐞𝐬𝐮𝐥𝐭𝐬:
TerraFM sets new benchmarks on GEO-Bench and Copernicus-Bench, demonstrating strong generalization across geographies, modalities, and tasks, including classification, segmentation, and landslide detection. The model achieves the highest accuracy on m-EuroSat while operating at significantly lower computational cost compared to other large-scale models.
𝐁𝐢𝐠𝐠𝐞𝐫 𝐢𝐦𝐩𝐚𝐜𝐭:
TerraFM represents a shift toward unified systems that can seamlessly combine different sensor types to provide more reliable insights. This approach could transform applications from precision agriculture and climate monitoring to disaster response, where the ability to integrate multiple data sources can mean the difference
between accurate assessment and missed critical changes.
Code
Model
|
|
|
|
|
|
 |
Insights: Foundation Models
Designing Foundation Models for Downstream Use
Everyone wants a general-purpose model. But in Earth observation, general doesn’t mean useful—unless it’s tailored to your downstream goal.
To get real value from a model, we have to align its design with the type of task we’re actually solving—retrieval, reasoning, prediction, or segmentation.
Let’s explore what each really demands:
🔍 Retrieval benefits from contrastive learning—models learn to bring semantically similar scenes (e.g., past droughts) closer in embedding space. But use this for classification, and subtle differences—like early-stage crop stress—may get flattened.
🤔 Reasoning needs attention-based models that integrate spatial and contextual cues—like satellite trends,
weather, and elevation—to answer complex queries: Why did forest loss spike here in 2022?
📈 Prediction favors discriminative, label-aligned features—ideal for land cover classification or yield forecasting. But these models can overfit to known categories and struggle with edge cases.
🧭 Segmentation demands pixel-level spatial precision—essential for delineating flood zones or burned areas. Without tight alignment, boundaries blur, and decision-making suffers.
🧩 𝗢𝗻𝗲 𝗺𝗼𝗱𝗲𝗹 𝘄𝗼𝗻’𝘁 𝗲𝘅𝗰𝗲𝗹 𝗮𝘁 𝗲𝘃𝗲𝗿𝘆 𝘁𝗮𝘀𝗸.
Yet too often we treat foundation models as one-size-fits-all.
Instead, we should ask:
- What do we need the model to do?
- What pretraining objective aligns best?
- How can we
fine-tune or adapt it with purpose?
📌 𝗔 𝗴𝗲𝗻𝗲𝗿𝗮𝗹-𝗽𝘂𝗿𝗽𝗼𝘀𝗲 𝗳𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹 𝗶𝘀𝗻’𝘁 𝘃𝗮𝗹𝘂𝗮𝗯𝗹𝗲 𝗯𝗲𝗰𝗮𝘂𝘀𝗲 𝗶𝘁’𝘀 𝗴𝗲𝗻𝗲𝗿𝗮𝗹—𝗯𝘂𝘁 𝗯𝗲𝗰𝗮𝘂𝘀𝗲 𝗶𝘁 𝗰𝗮𝗻 𝗯𝗲 𝘁𝗮𝗶𝗹𝗼𝗿𝗲𝗱.
Let’s stop chasing generic capability—and start designing for downstream impact.
Intentional model design isn’t extra
work—it’s what turns foundation models into solutions.
👇 𝐖𝐡𝐚𝐭 𝐭𝐚𝐬𝐤 𝐚𝐫𝐞 𝐲𝐨𝐮 𝐝𝐞𝐬𝐢𝐠𝐧𝐢𝐧𝐠 𝐟𝐨𝐫—𝐚𝐧𝐝 𝐰𝐡𝐚𝐭 𝐭𝐫𝐚𝐝𝐞𝐨𝐟𝐟𝐬 𝐚𝐫𝐞 𝐲𝐨𝐮 𝐰𝐢𝐥𝐥𝐢𝐧𝐠 𝐭𝐨 𝐦𝐚𝐤𝐞?
Leave a comment
|
|
|
|
|
|
 |
Insights: Pharma
𝗧𝗵𝗲 “𝗟𝗮𝘀𝘁-𝗠𝗶𝗹𝗲 𝗔𝗜 𝗚𝗮𝗽” 𝗶𝗻 𝗣𝗵𝗮𝗿𝗺𝗮: 𝗧𝗵𝗲 𝗥𝗶𝘀𝗸 𝗡𝗼 𝗢𝗻𝗲 𝗜𝘀 𝗔𝗰𝗰𝗼𝘂𝗻𝘁𝗮𝗯𝗹𝗲 𝗙𝗼𝗿
👉 𝗔𝗻𝗱 𝘁𝗵𝗲 𝗰𝗼𝘀𝘁 𝗼𝗳 𝗹𝗲𝗮𝘃𝗶𝗻𝗴 𝗶𝘁
𝘂𝗻𝗼𝘄𝗻𝗲𝗱 𝗰𝗮𝗻 𝗿𝗲𝗮𝗰𝗵 $𝟮𝟬𝟬𝗠 𝗽𝗲𝗿 𝘁𝗿𝗶𝗮𝗹.
One oncology program I followed looked ready to launch. Discovery data was strong. Internal validation was clean. But during regulatory review, agencies asked for multi-site evidence.
Performance dropped.
◉ Scanners varied
◉ Staining protocols weren’t identical
◉ Patient cohorts were more diverse than expected
𝗧𝗵𝗲 𝗿𝗲𝘀𝘂𝗹𝘁? 𝟵 𝗺𝗼𝗻𝘁𝗵𝘀 𝗼𝗳 𝗱𝗲𝗹𝗮𝘆, $𝟭𝟱𝗠 𝗶𝗻 𝗿𝗲-𝘃𝗮𝗹𝗶𝗱𝗮𝘁𝗶𝗼𝗻
𝗰𝗼𝘀𝘁𝘀, 𝗮𝗻𝗱 𝗮 𝗹𝗼𝘀𝘁 𝗰𝗼𝗺𝗽𝗲𝘁𝗶𝘁𝗶𝘃𝗲 𝘄𝗶𝗻𝗱𝗼𝘄.
𝗧𝗵𝗶𝘀 𝘄𝗮𝘀𝗻’𝘁 𝗮 𝗳𝗮𝗶𝗹𝘂𝗿𝗲 𝗼𝗳 𝘀𝗰𝗶𝗲𝗻𝗰𝗲. 𝗜𝘁 𝘄𝗮𝘀 𝗮 𝗳𝗮𝗶𝗹𝘂𝗿𝗲 𝗼𝗳 𝗼𝘄𝗻𝗲𝗿𝘀𝗵𝗶𝗽.
𝗛𝗲𝗿𝗲’𝘀 𝗵𝗼𝘄 𝗿𝗲𝘀𝗽𝗼𝗻𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀
𝗮𝗿𝗲 𝘁𝘆𝗽𝗶𝗰𝗮𝗹𝗹𝘆 𝘀𝗽𝗹𝗶𝘁:
◉ 𝗜𝗻𝘁𝗲𝗿𝗻𝗮𝗹 𝗥&𝗗 → discovery and translational science
◉ 𝗖𝗥𝗢𝘀 → logistics and execution
◉ 𝗩𝗲𝗻𝗱𝗼𝗿𝘀 → tools and platforms
◉ 𝗥𝗲𝗴𝘂𝗹𝗮𝘁𝗼𝗿𝘀 → enforce robustness, but only after programs are locked
𝗕𝘆 𝘁𝗵𝗲𝗻, 𝗶𝘁’𝘀 𝘁𝗼𝗼 𝗹𝗮𝘁𝗲. Fixes are slow, costly, and credibility is already at risk.
𝗧𝗵𝗮𝘁 𝗺𝗶𝘀𝘀𝗶𝗻𝗴
𝗼𝘄𝗻𝗲𝗿𝘀𝗵𝗶𝗽 𝗲𝗮𝗿𝗹𝗶𝗲𝗿 𝗶𝗻 𝘁𝗵𝗲 𝗽𝗿𝗼𝗰𝗲𝘀𝘀 𝗶𝘀 𝘁𝗵𝗲 𝗹𝗮𝘀𝘁-𝗺𝗶𝗹𝗲 𝗔𝗜 𝗴𝗮𝗽.
📊 𝗪𝗵𝘆 𝗶𝘁 𝗺𝗮𝘁𝘁𝗲𝗿𝘀:
◉ Phase 2 oncology trials cost $𝟮𝟬–𝟰𝟬𝗠
◉ Phase 3 trials cost $𝟮𝟬𝟬–𝟯𝟬𝟬𝗠
◉ A 6–12 month delay can mean $𝟭𝟬𝟬–𝟮𝟬𝟬𝗠 in lost revenue
💡 𝗠𝘆 𝗿𝗼𝗹𝗲 𝗶𝘀 𝘁𝗼
𝗰𝗹𝗼𝘀𝗲 𝘁𝗵𝗮𝘁 𝗹𝗮𝘀𝘁-𝗺𝗶𝗹𝗲 𝗴𝗮𝗽 — helping pharma teams surface robustness and data issues early, when fixes take weeks, not months, and before regulators find the cracks.
Across a portfolio with dozens of oncology programs, even small improvements compound into hundreds of millions protected and stronger regulatory credibility.
👉 Hit reply if you’d like to see how pharma teams are building robustness oversight into their biomarker strategies to reduce portfolio risk and protect competitive position.
|
|
|
|
|
|
 |
Research: Benchmark
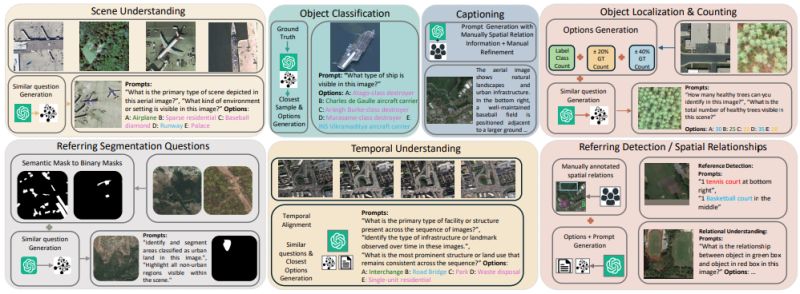
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks
Imagine needing to count damaged buildings after a disaster, identify crop types from satellite imagery, or track temporal changes in urban development. These geospatial tasks require sophisticated visual understanding that goes far beyond typical AI benchmarks—yet until now, we had no standardized way to evaluate how well AI models handle such challenges.
New research by Danish et al. introduces GEOBench-VLM, addressing a critical gap in how we assess vision-language models for real-world geospatial applications.
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬:
Geospatial data presents unique challenges: objects vary dramatically in scale, imaging
conditions change constantly, and many applications require temporal analysis to detect changes over time. Traditional benchmarks like SEED-Bench and MMMU don't capture these complexities, making it impossible to assess whether AI systems can handle real-world Earth observation tasks.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
◦ 𝐂𝐨𝐦𝐩𝐫𝐞𝐡𝐞𝐧𝐬𝐢𝐯𝐞 𝐬𝐜𝐨𝐩𝐞: 31 fine-grained tasks across 8 categories—scene understanding, object classification, counting, event detection, captioning, segmentation, temporal analysis, and non-optical data processing
◦ 𝐑𝐞𝐚𝐥-𝐰𝐨𝐫𝐥𝐝 𝐫𝐢𝐠𝐨𝐫: Over 10k manually verified instructions spanning diverse
visual conditions, object types, and scales from satellite and aerial imagery
◦ 𝐌𝐮𝐥𝐭𝐢-𝐦𝐨𝐝𝐚𝐥 𝐜𝐨𝐯𝐞𝐫𝐚𝐠𝐞: Includes optical, multispectral, SAR, and temporal data to reflect the full spectrum of Earth observation challenges
◦ 𝐒𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞𝐝 𝐞𝐯𝐚𝐥𝐮𝐚𝐭𝐢𝐨𝐧: Multiple-choice format enables objective, scalable assessment while preventing hallucinations common in open-ended responses
𝐓𝐡𝐞 𝐫𝐞𝐬𝐮𝐥𝐭𝐬:
Even state-of-the-art models struggle significantly. LLaVA-OneVision achieved the best performance at just 42% accuracy—only slightly better than random guessing. GPT-4o excelled in object
classification, while different models showed varying strengths. No single model dominated across all tasks. Models struggle with numerical reasoning in counting tasks, show high sensitivity to prompt variations, and fail to effectively leverage temporal information for change detection.
𝐁𝐢𝐠𝐠𝐞𝐫 𝐢𝐦𝐩𝐚𝐜𝐭:
GEOBench-VLM provides the foundation for developing AI systems capable of handling real-world Earth observation challenges—from disaster response and environmental monitoring to urban planning and climate analysis. By revealing where current models fall short, it charts a path toward more capable geospatial AI that could transform how we understand and respond to changes on our planet.
Code
Dataset
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Pixel Clarity Call - A free 30-minute conversation to cut through the noise and see where your vision AI project really stands. We’ll pinpoint vulnerabilities, clarify your biggest challenges, and decide if an assessment or diagnostic could save you time, money, and credibility.
Book now
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
