 |
Insights: Drug Development
𝗜𝗻 𝗼𝗻𝗰𝗼𝗹𝗼𝗴𝘆 𝗥&𝗗, 𝗲𝘃𝗲𝗻 𝗮 𝘀𝗶𝘅-𝗺𝗼𝗻𝘁𝗵 𝗱𝗲𝗹𝗮𝘆 𝗰𝗮𝗻 𝗰𝗼𝘀𝘁 $𝟭𝟬𝟬–𝟮𝟬𝟬𝗠 𝗶𝗻 𝗹𝗼𝘀𝘁 𝗿𝗲𝘃𝗲𝗻𝘂𝗲.
One biopharma team I followed was gearing up for a global trial. The science looked strong. But just before launch, regulators requested more validation data across diverse cohorts.
The team had the resources
— but not the time. By the time re-validation was complete, their competitors had published results and advanced their own trial. The opportunity for first-mover advantage was gone.
📊 𝗧𝗵𝗶𝘀 𝗶𝘀 𝗯𝗲𝗰𝗼𝗺𝗶𝗻𝗴 𝗺𝗼𝗿𝗲 𝗰𝗼𝗺𝗺𝗼𝗻:
- 70% of Phase 3 oncology trials now include biomarkers (FDA, 2022).
- Regulators expect robustness across geographies, sites, and populations.
- The oncology pipeline is more crowded than ever — over 2,000 active drugs in development (IQVIA).
The science may be solid. But if robustness isn’t proven early, the clock becomes your biggest risk.
👉 Where does timing feel most fragile in your programs — regulatory review, trial launch, or competitive positioning?
💡 In today’s oncology landscape,
biomarker readiness is as much about strategic timing as scientific accuracy.
I’ve created a short framework on how teams are building early oversight into their programs to stay ahead. Hit reply if you’d like a copy.
|
|
|
|
|
|
 |
Research: Vision-Language for EO
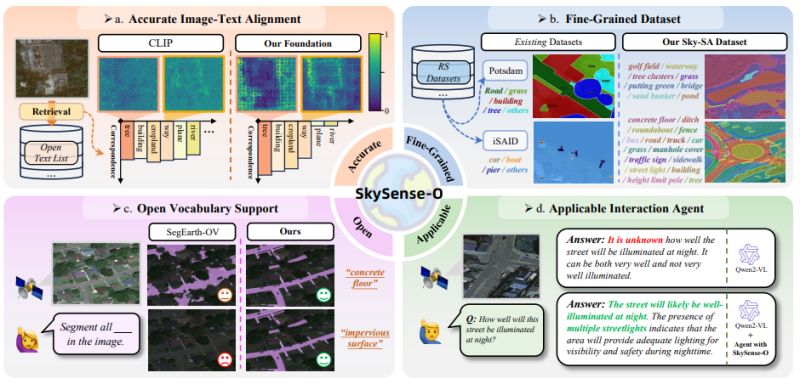
SkySense-O: Towards Open-World Remote Sensing Interpretation with Vision-Centric Visual-Language Modeling
What if an AI could understand and interpret satellite imagery with the versatility of human perception, recognizing everything from "concrete floor" to "industrial park" without being limited to predefined categories?
Qi Zhu et al. introduced SkySense-O at CVPR 2025 - a vision-centric foundation model that achieves true open-world interpretation of remote sensing imagery, outperforming existing models by significant margins across diverse tasks.
𝐓𝐡𝐞 𝐨𝐩𝐞𝐧-𝐰𝐨𝐫𝐥𝐝 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞: Current remote sensing AI models are constrained by limited semantic categories and struggle with
the dense, intricate spatial distributions typical of satellite imagery. Most existing datasets have sparse annotations or lack diversity in category descriptions, preventing true open-world understanding where models can recognize and describe any object or land feature they encounter.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
∙ 𝐒𝐤𝐲-𝐒𝐀 𝐝𝐚𝐭𝐚𝐬𝐞𝐭: Largest open-world remote sensing dataset with 183k image-text pairs covering 1.7k category labels - far exceeding existing datasets
∙ 𝐕𝐢𝐬𝐢𝐨𝐧-𝐜𝐞𝐧𝐭𝐫𝐢𝐜 𝐦𝐨𝐝𝐞𝐥𝐢𝐧𝐠: Novel approach that prioritizes visual representation over language dependencies to better distinguish
spatially complex remote sensing objects
∙ 𝐕𝐢𝐬𝐮𝐚𝐥-𝐜𝐞𝐧𝐭𝐫𝐢𝐜 𝐤𝐧𝐨𝐰𝐥𝐞𝐝𝐠𝐞 𝐠𝐫𝐚𝐩𝐡: GPT-4V-powered system that measures visual similarity between categories to improve training sample selection
∙ 𝐎𝐩𝐞𝐧-𝐭𝐞𝐱𝐭 𝐚𝐧𝐧𝐨𝐭𝐚𝐭𝐢𝐨𝐧: Fill-in-the-blank labeling approach enabling truly open vocabulary understanding
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬: SkySense-O achieved state-of-the-art performance across 14 zero-shot datasets, outperforming recent models like SegEarth-OV and GeoRSCLIP. More importantly, the vision-centric
approach addresses a fundamental challenge in remote sensing AI - the ability to distinguish between visually similar but contextually different objects in complex satellite imagery.
This work represents a significant step toward general-purpose remote sensing AI that can adapt to new scenarios and categories without requiring task-specific training, making advanced Earth observation capabilities more accessible across applications.
|
|
|
|
|
|
 |
Blog: Latest in Computer Vision
What’s New in Computer Vision? Key Insights from CVPR 2025
Foundation models aren’t just for natural images anymore.
Multimodal interfaces are moving beyond chatbots.
And agentic AI? It’s no longer sci-fi—it’s tackling real-world workflows.
At CVPR 2025, the most exciting advances weren’t just technical—they redefined how we build, interact with, and deploy vision systems.
In this article, I unpack:
🔹 Why domain-specific foundation models are becoming essential
🔹 How vision-language models are making tools far more usable
🔹 What multi-agent systems mean for diagnosis, earth observation, and clinical decision-making
🔹 The key takeaways for healthcare, agtech, and environmental AI teams
|
|
|
|
|
|
 |
Insights: Model Shortcuts
𝗪𝗵𝗮𝘁 𝗛𝗮𝗽𝗽𝗲𝗻𝘀 𝗪𝗵𝗲𝗻 𝗠𝗼𝗱𝗲𝗹𝘀 𝗟𝗲𝗮𝗿𝗻 𝗪𝗵𝗮𝘁 𝗪𝗲 𝗗𝗶𝗱𝗻’𝘁 𝗠𝗲𝗮𝗻 𝘁𝗼 𝗧𝗲𝗮𝗰𝗵?
In machine learning, “domain shift” is usually something to be minimized.But in Earth observation, domain shift is often the very reason we need foundation models in the first place.
We want models that work across:
🌦️ 𝗖𝗹𝗶𝗺𝗮𝘁𝗲 𝘇𝗼𝗻𝗲𝘀 (e.g., tundra to tropics)
🛰️ 𝗦𝗲𝗻𝘀𝗼𝗿 𝘁𝘆𝗽𝗲𝘀 (e.g., Sentinel-2, Landsat, Planet)
📅 𝗧𝗶𝗺𝗲 (e.g., drought years, land-use change, phenology)
That means building models robust to variation—not just within the training distribution, but outside
it.
But what counts as variation? Not all domain shifts are equally meaningful.
In EO, 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗮𝗻𝗱 𝗽𝗵𝘆𝘀𝗶𝗰𝗮𝗹 𝘃𝗮𝗿𝗶𝗮𝘁𝗶𝗼𝗻 𝗼𝗳𝘁𝗲𝗻 𝗰𝗼-𝗼𝗰𝗰𝘂𝗿—but they’re not the same. Models need to distinguish meaningful land cover change from incidental differences in elevation, lighting, or geography.
For example, models that encode 𝗹𝗮𝘁𝗶𝘁𝘂𝗱𝗲, 𝗹𝗼𝗻𝗴𝗶𝘁𝘂𝗱𝗲, 𝗼𝗿 𝗲𝗹𝗲𝘃𝗮𝘁𝗶𝗼𝗻 directly can fall into shortcut learning: instead of focusing
on spectral or spatial features, they learn to associate outcomes with locations nearby in training. It’s a quick win—but a brittle one.
That shortcut works—until it doesn’t.
- A land cover model trained in Europe might overfit to elevation rather than vegetation patterns.
- A wildfire model may mistake geographic proximity for fire risk.
Sometimes signals like elevation do matter—e.g., in flood or landslide prediction. But often, they just correlate with the labels in the training set.
🔍 The key is 𝗱𝗶𝘀𝗲𝗻𝘁𝗮𝗻𝗴𝗹𝗶𝗻𝗴 𝗽𝗵𝘆𝘀𝗶𝗰𝗮𝗹 𝗳𝗿𝗼𝗺 𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗳𝗲𝗮𝘁𝘂𝗿𝗲𝘀, and deciding when a signal is informative vs
spurious.
That’s why smart modelers:
- 𝗔𝘂𝗱𝗶𝘁 their inputs for spurious correlations
- 𝗙𝗶𝗹𝘁𝗲𝗿 or regularize signals like lat/lon when inappropriate
- 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗲 on geographies that break the training shortcuts
📌 𝗔 𝗴𝗼𝗼𝗱 𝗳𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹 𝗳𝗼𝗿 𝗘𝗢 𝗱𝗼𝗲𝘀𝗻’𝘁 𝗷𝘂𝘀𝘁 𝘁𝗼𝗹𝗲𝗿𝗮𝘁𝗲 𝗱𝗼𝗺𝗮𝗶𝗻 𝘀𝗵𝗶𝗳𝘁—𝗶𝘁
𝘀𝘂𝗿𝘃𝗶𝘃𝗲𝘀 𝗹𝗼𝘀𝗶𝗻𝗴 𝗶𝘁𝘀 𝗰𝗿𝘂𝘁𝗰𝗵𝗲𝘀.
🧭 Because in Earth observation, 𝗴𝗲𝗻𝗲𝗿𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗶𝘀𝗻’𝘁 𝗮𝗯𝗼𝘂𝘁 𝗳𝗶𝘁𝘁𝗶𝗻𝗴 𝘁𝗵𝗲 𝗽𝗮𝘀𝘁—𝗶𝘁’𝘀 𝗮𝗯𝗼𝘂𝘁 𝗽𝗿𝗲𝗽𝗮𝗿𝗶𝗻𝗴 𝗳𝗼𝗿 𝘄𝗵𝗮𝘁’𝘀 𝗻𝗲𝘅𝘁.
👇 When have you seen geographic cues help a model—and when have they
hurt?
Leave a comment
|
|
|
|
|
|
 |
Research: Bias
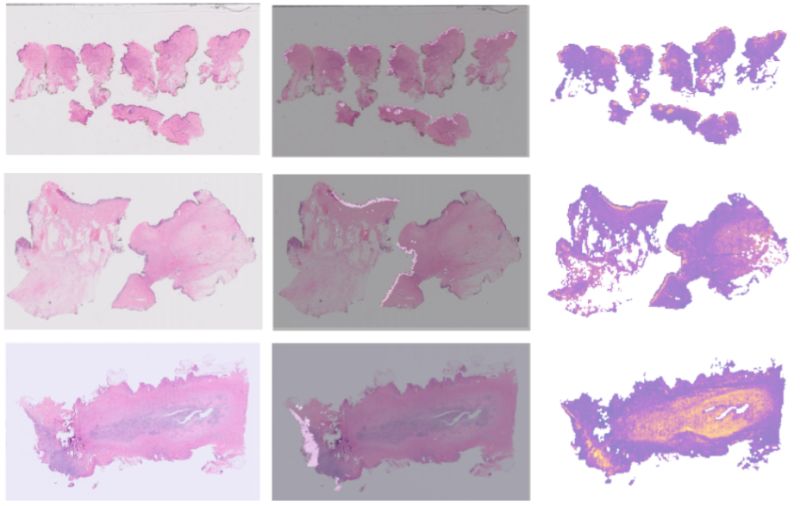
Predict Patient Self-reported Race from Skin Histological Images
Shengjia Chen et al. discovered that deep learning models can identify patients' self-reported race from digitized skin tissue samples with concerning accuracy (AUC: 0.663-0.799). This raises critical questions about hidden biases in medical AI.
Why this matters: Bias and disparities in ML-based biomedical and healthcare applications have been widely studied, but demographic shortcuts in computational pathology remain understudied. As AI increasingly supports diagnostic decisions, understanding these unintended capabilities is essential for healthcare equity.
Key findings:
- Models predicted race most accurately for White and Black patients
- The epidermis emerged as the primary predictive feature — when removed, performance
dropped significantly across all groups
- Disease-related confounding inflated prediction performance, highlighting how sampling biases can create misleading shortcuts
The innovation: They used attention-based multiple instance learning with foundation models to identify which tissue regions drove predictions. Their UMAP visualization technique revealed that models focus heavily on epidermal structures, likely reflecting melanin-related morphological differences.
Clinical implications: If diagnostic AI models inadvertently learn these demographic patterns, they could perpetuate healthcare disparities by making different quality predictions across racial groups. The findings highlight the need for careful data curation and bias mitigation to ensure equitable AI deployment in pathology.
This work underscores a fundamental challenge: even when demographic information isn't explicitly provided, AI can extract it from biological data in ways we're
only beginning to understand.
Have you encountered algorithmic bias in your healthcare organization? What steps are you taking to address it?
Leave a comment
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Pixel Clarity Call - A free 30-minute conversation to cut through the noise and see where your vision AI project really stands. We’ll pinpoint vulnerabilities, clarify your biggest challenges, and decide if an assessment or diagnostic could save you time, money, and credibility.
Book now
Last-Mile AI Gap Diagnostic - A 90-minute diagnostic plus a written summary to catch problems early in an active project. We’ll review your current approach, pinpoint vulnerabilities, and give you a roadmap to course-correct before issues compound into last-mile failures.
Book now
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
