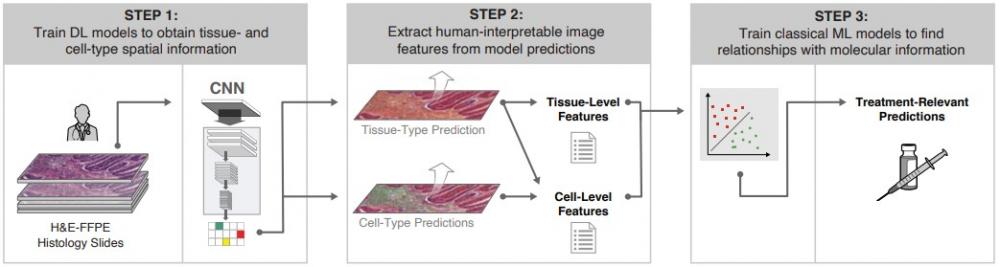
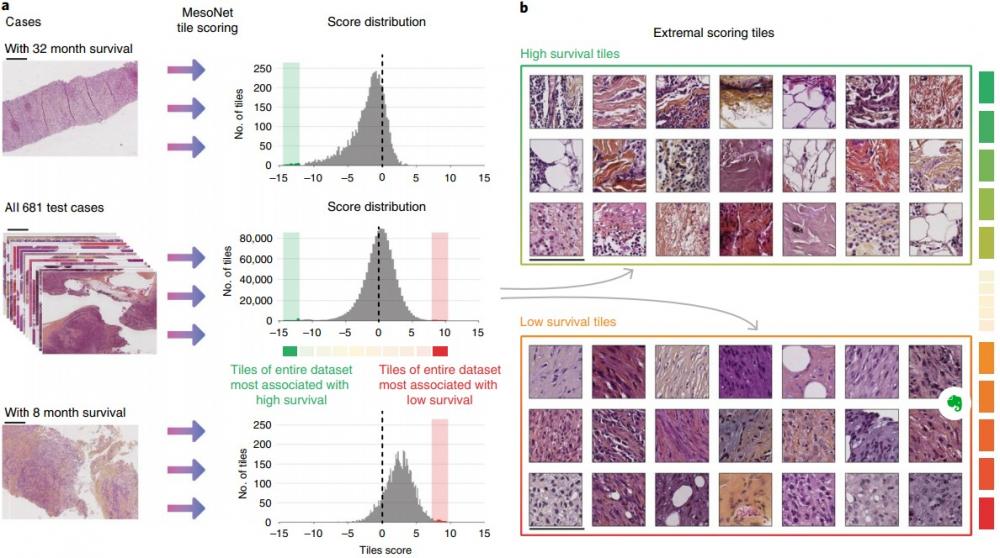
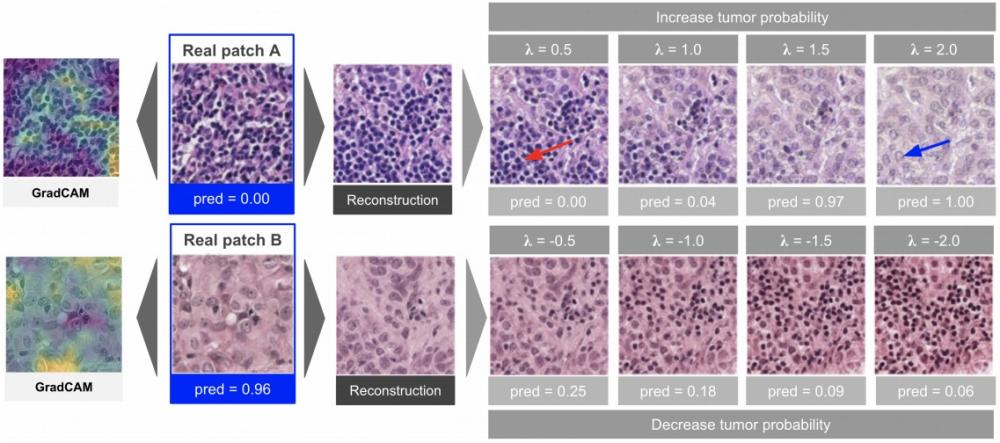
[3] Using StyleGAN for Visual Interpretability of Deep Learning Models on Medical Images - synopsis
There are a number of other explainability techniques out there, like pixel attribution methods (e.g., GradCAM in the image above). Be sure to consider your use case as you select a method.
Explainability is important for debugging models, but also for ensuring model fairness and identifying potential biases. Interpretable models can even help make new scientific discoveries!
Do you know someone who would be interested in these insights?
Please forward this email along. Go here to sign up
Hope that you’re finding Pathology ML Insights informative. Look out for another edition in two weeks.
Heather
|