 |
Blog: CV Development
Avoid These 3 Pitfalls That Quietly Derail Computer Vision Projects
𝗬𝗼𝘂𝗿 𝗺𝗲𝘁𝗿𝗶𝗰𝘀 𝗹𝗼𝗼𝗸 𝗴𝗿𝗲𝗮𝘁—𝘂𝗻𝘁𝗶𝗹 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗵𝗶𝘁𝘀 𝘁𝗵𝗲 𝗿𝗲𝗮𝗹 𝘄𝗼𝗿𝗹𝗱. Then it fails—quietly, and expensively.
I've seen teams lose months of progress—not because their model was wrong, but because their 𝘥𝘢𝘵𝘢 𝘴𝘦𝘵𝘶𝘱 was.
The patterns are surprisingly consistent. Auditing CV projects
across pathology, life science, and the environment, I keep seeing the same 3 hidden pitfalls:
- Noisy or inconsistent labels
- Skipping baselines (so you're flying blind)
- Data leakage that makes metrics look great—until deployment
These aren't engineering bugs. They're 𝗽𝗿𝗼𝗰𝗲𝘀𝘀 𝗳𝗮𝗶𝗹𝘂𝗿𝗲𝘀—and they quietly erode real-world performance, even when the metrics look great.
I unpack the 3 most common failure patterns—and how to spot them 𝘣𝘦𝘧𝘰𝘳𝘦 𝘵𝘩𝘦𝘺 𝘲𝘶𝘪𝘦𝘵𝘭𝘺 𝘥𝘦𝘳𝘢𝘪𝘭 𝘺𝘰𝘶𝘳 𝘯𝘦𝘹𝘵 𝘮𝘪𝘭𝘦𝘴𝘵𝘰𝘯𝘦.
|
|
|
|
|
|
 |
Research: Agents for Oncology
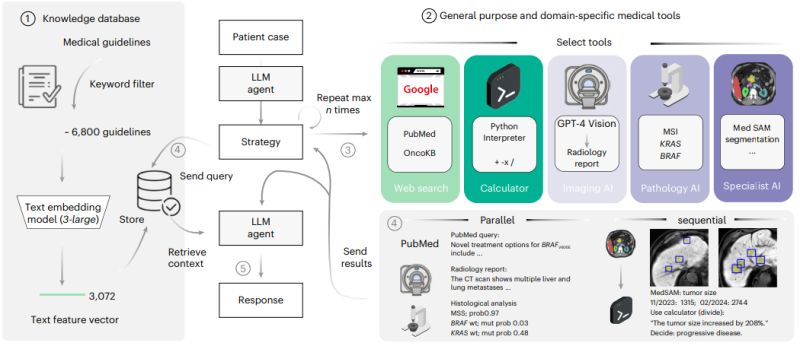
Development and validation of an autonomous artificial intelligence agent for clinical decision-making in oncology
Oncology decision-making is notoriously complex. Clinicians must integrate histopathology images, radiology scans, genetic profiles, and ever-evolving treatment guidelines to make personalized care decisions. It's a cognitive challenge that even experienced specialists find demanding.
A new study by Ferber et al. in Nature Cancer shows how an autonomous AI agent tackled this complexity head-on—and the results are striking.
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀:
Current AI approaches in healthcare often work in isolation—analyzing single data types or providing generic responses. But real clinical decisions require synthesizing multiple
sources of evidence simultaneously, something that has remained challenging for AI systems.
𝗞𝗲𝘆 𝗶𝗻𝗻𝗼𝘃𝗮𝘁𝗶𝗼𝗻𝘀:
◦ 𝐌𝐮𝐥𝐭𝐢𝐦𝐨𝐝𝐚𝐥 𝐭𝐨𝐨𝐥 𝐢𝐧𝐭𝐞𝐠𝐫𝐚𝐭𝐢𝐨𝐧: Vision transformers detect genetic mutations directly from tissue slides, MedSAM segments tumors in radiology images, and the system queries precision oncology databases autonomously
◦ 𝐒𝐞𝐪𝐮𝐞𝐧𝐭𝐢𝐚𝐥 𝐫𝐞𝐚𝐬𝐨𝐧𝐢𝐧𝐠: The agent chains tools together—first measuring tumor growth from imaging, then checking mutation databases, then searching recent literature
◦
𝐄𝐯𝐢𝐝𝐞𝐧𝐜𝐞-𝐛𝐚𝐬𝐞𝐝 𝐜𝐢𝐭𝐚𝐭𝐢𝐨𝐧𝐬: 75.5% accuracy in citing relevant medical guidelines, addressing the critical problem of AI hallucinations in healthcare
𝗧𝗵𝗲 𝗿𝗲𝘀𝘂𝗹𝘁𝘀:
When tested on 20 realistic patient cases, the integrated system achieved 91% accuracy in clinical conclusions. Perhaps more telling: GPT-4 alone managed only 30% accuracy on the same cases—nearly a 3x improvement through tool integration.
The agent successfully used appropriate diagnostic tools 87.5% of the time and provided helpful responses to 94% of clinical questions.
𝗧𝗵𝗲 𝗯𝗶𝗴𝗴𝗲𝗿 𝗽𝗶𝗰𝘁𝘂𝗿𝗲:
This isn't
about replacing oncologists—it's about augmenting clinical reasoning with AI that can process multiple data streams simultaneously. The modular approach means individual tools can be updated, validated, and regulated independently.
While challenges remain around data privacy and regulatory approval, this research points toward a future where AI agents serve as sophisticated clinical reasoning partners, helping doctors navigate the increasing complexity of modern medicine.
|
|
|
|
|
|
 |
Insights: Foundation Models for EO
Why Foundation Models are a Game Changer for Earth Observation
In the past few years, foundation models have reshaped the landscape of machine learning. First in NLP, then vision—and now they’re gaining traction in Earth Observation.
But what does that mean for this field?
At their core, 𝗳𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹𝘀 are large, pretrained models trained on massive, diverse datasets with broad objectives—like predicting missing image patches or aligning image–text pairs. Once trained, they can be adapted (or 𝗽𝗿𝗼𝗺𝗽𝘁𝗲𝗱) for a variety of downstream tasks.
For EO, this opens up powerful
possibilities:
🔍 𝗙𝗲𝘄𝗲𝗿 𝗹𝗮𝗯𝗲𝗹𝘀 𝗻𝗲𝗲𝗱𝗲𝗱: Instead of training a new model from scratch for each task and geography, we can prompt or reuse a general model.
🌍 𝗚𝗹𝗼𝗯𝗮𝗹 𝗴𝗲𝗻𝗲𝗿𝗮𝗹𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Models trained on diverse, multi-sensor EO data can potentially work across countries, seasons, or satellites.
🧩 𝗥𝗶𝗰𝗵 𝗿𝗲𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻𝘀: Embeddings learned from foundation models can capture nuanced patterns of land cover, vegetation health, urban form, and more—even in the absence of human labels.
This
shift isn’t just about performance—it’s about efficiency, scalability, and accelerating real-world impact.
But it also raises new questions:
- What kind of foundation models do we 𝗿𝗲𝗮𝗹𝗹𝘆 need for EO tasks?
- Do current architectures capture the spatiotemporal structure of EO data?
- What biases are we baking in through our sampling, masking, and pretraining choices?
Over the next few posts, I’ll dig into:
- Why embedding design matters more than we think
- How hidden biases creep into “self-supervised” pipelines
- What should count as generalization in remote sensing
- What we risk when we treat foundation models as one-size-fits-all
- … and how we can build better, more transparent EO models going forward
𝗪𝗵𝗮𝘁 𝗲𝘅𝗰𝗶𝘁𝗲𝘀—𝗼𝗿
𝗰𝗼𝗻𝗰𝗲𝗿𝗻𝘀—𝘆𝗼𝘂 𝗺𝗼𝘀𝘁 𝗮𝗯𝗼𝘂𝘁 𝗳𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹𝘀 𝗶𝗻 𝗘𝗢?
|
|
|
|
|
|
 |
Research: Foundation Model for Cytology
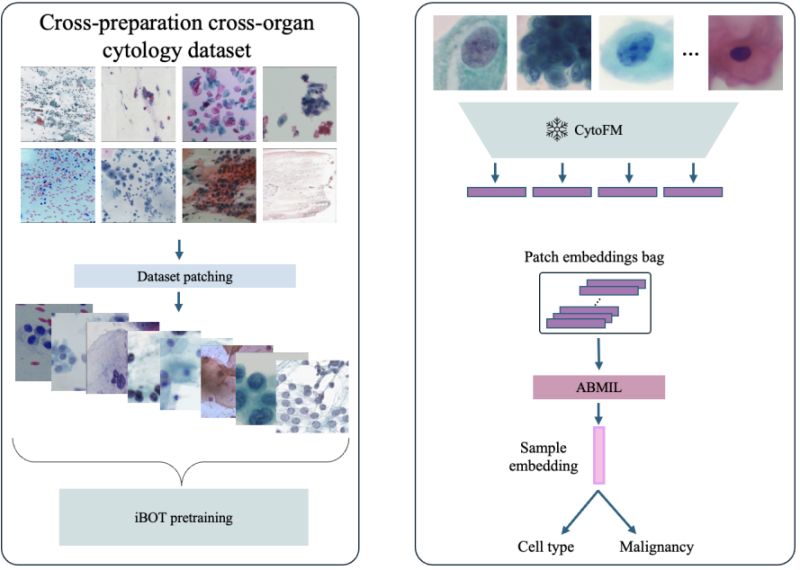
CytoFM: The first cytology foundation model
How do you diagnose cancer when you need to identify just a few abnormal cells among millions in a microscopy slide? Cytology - the examination of individual cells - is crucial for early cancer detection, but its labor-intensive nature creates diagnostic delays that can impact patient outcomes.
Vedrana Ivezic et al. introduced CytoFM at the CVPR 2025 Workshop on Computer Vision for Microscopy Image Analysis - the first foundation model specifically trained on cytology data to capture the unique cellular features that matter for cancer diagnosis.
𝐓𝐡𝐞 𝐜𝐲𝐭𝐨𝐥𝐨𝐠𝐲 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞: Unlike
histopathology, which examines tissue structure, cytology focuses on individual cell morphology and rare diagnostic cells scattered across gigapixel slides. Existing foundation models trained on natural images or histopathology data struggle to capture these cytology-specific features. The field also lacks large, diverse annotated datasets due to the specialized expertise required and variations in staining and preparation methods across institutions.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
∙ 𝐌𝐮𝐥𝐭𝐢-𝐢𝐧𝐬𝐭𝐢𝐭𝐮𝐭𝐢𝐨𝐧𝐚𝐥 𝐝𝐚𝐭𝐚𝐬𝐞𝐭: 1.4 million patches from eight datasets spanning breast, cervical, and thyroid cytology across seven institutions
∙
𝐢𝐁𝐎𝐓 𝐬𝐞𝐥𝐟-𝐬𝐮𝐩𝐞𝐫𝐯𝐢𝐬𝐞𝐝 𝐩𝐫𝐞𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠: Combines masked image modeling with self-distillation to learn both low-level cellular features and high-level context
∙ 𝐂𝐲𝐭𝐨𝐥𝐨𝐠𝐲-𝐚𝐰𝐚𝐫𝐞 𝐚𝐭𝐭𝐞𝐧𝐭𝐢𝐨𝐧: Model learns to focus on diagnostically relevant features like cell morphology, mitotic activity, and nuclear boundaries
∙ 𝐌𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐢𝐧𝐬𝐭𝐚𝐧𝐜𝐞 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠: Aggregates patch-level features for
slide-level diagnosis without requiring expensive patch-level annotations
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬: CytoFM outperformed both natural image and histopathology foundation models on 2 out of 3 downstream tasks, including cervical cancer classification and cell type identification. Importantly, it showed strong generalization to completely unseen datasets from different institutions without additional fine-tuning, addressing a key challenge in deploying AI across diverse clinical settings.
This work demonstrates that domain-specific foundation models can learn meaningful representations even from relatively small datasets, opening new possibilities for AI-assisted cytology screening and diagnosis.
|
|
|
|
|
|
 |
Research: Geospatial Agents
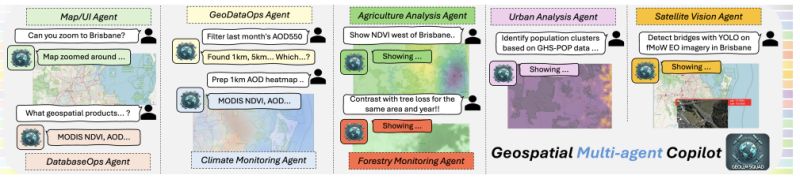
Multi-Agent Geospatial Copilots for Remote Sensing Workflows
Remote sensing workflows are inherently complex. A geoscientist analyzing climate change might need to process satellite imagery, cross-reference weather data, and switch between different sensors based on cloud coverage—all while applying years of domain expertise. Traditional AI approaches struggle with this complexity, often hitting walls when tasks become interdependent.
New research by Lee et al. introduces GeoLLM-Squad, demonstrating how multi-agent AI can transform Earth observation workflows by mimicking how human experts actually work.
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬:
Current geospatial copilots rely on monolithic large
language models that become bottlenecks when handling diverse, interconnected tasks. They're like trying to solve every problem with a single tool instead of assembling the right specialist for each job. As Earth observation data grows exponentially, we need smarter orchestration.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
◦ 𝐒𝐞𝐩𝐚𝐫𝐚𝐭𝐞𝐝 𝐨𝐫𝐜𝐡𝐞𝐬𝐭𝐫𝐚𝐭𝐢𝐨𝐧: Rather than one model doing everything, GeoLLM-Squad separates task coordination from specialized geospatial problem-solving
◦ 𝐒𝐩𝐞𝐜𝐢𝐚𝐥𝐢𝐳𝐞𝐝 𝐬𝐮𝐛-𝐚𝐠𝐞𝐧𝐭𝐬: Different agents handle urban
monitoring, forestry protection, climate analysis, and agriculture studies—each optimized for their domain
◦ 𝐌𝐨𝐝𝐮𝐥𝐚𝐫 𝐢𝐧𝐭𝐞𝐠𝐫𝐚𝐭𝐢𝐨𝐧: Built on open-source AutoGen and GeoLLM-Engine frameworks, enabling flexible deployment across diverse applications
𝐓𝐡𝐞 𝐫𝐞𝐬𝐮𝐥𝐭𝐬:
While single-agent systems struggle to scale with increasing task complexity, GeoLLM-Squad maintains robust performance across domains. The system achieved 17% improvement in agentic correctness over state-of-the-art baselines, with particularly strong results in vegetation monitoring and land coverage analysis.
𝐁𝐢𝐠𝐠𝐞𝐫 𝐢𝐦𝐩𝐚𝐜𝐭:
This research addresses a critical gap in
Earth observation capabilities. From tracking deforestation to monitoring urban sprawl to analyzing climate patterns, we need AI systems that can handle the inherent complexity of geospatial analysis. The multi-agent approach offers a path toward more sophisticated, domain-aware AI that scales with real-world complexity.
The implications extend beyond remote sensing—any field requiring coordinated analysis across multiple domains could benefit from this orchestration paradigm.
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Office Hours -- Are you a student with questions about machine learning for pathology or remote sensing? Do you need career advice? Once a month, I'm available to chat about your research, industry trends, career opportunities, or other topics.
Register for the next session
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
