Hi , Getting a machine learning model to work on your dataset is one thing, but validating that it will perform as intended on other image sets is a challenge of its own -- yet an extremely critical one!
Difficulties due to image variations caused by different staining protocols and scanners are well known, but what other considerations must be made when validating a model?
Hidden Variables
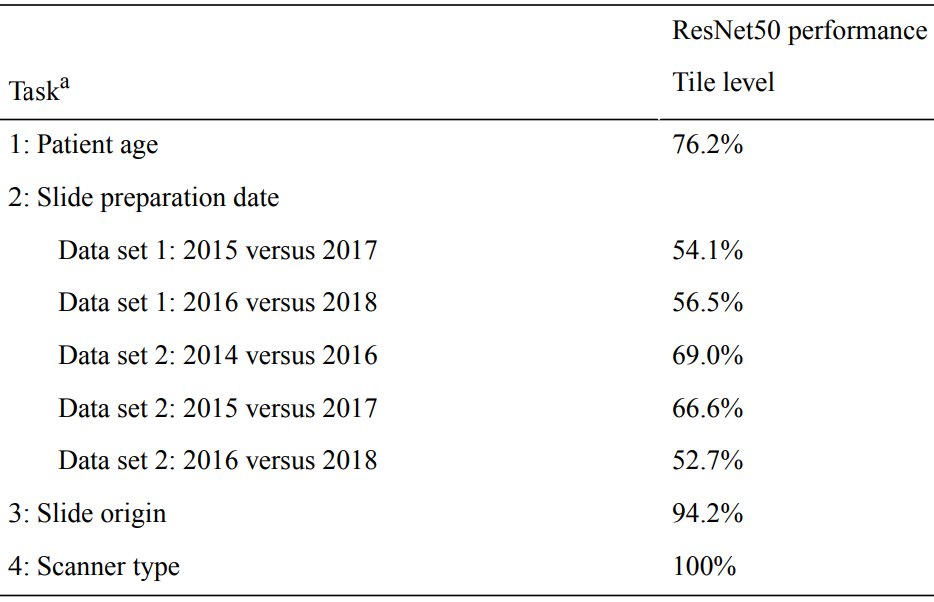
Schmitt et al. studied patient age, slide preparation date, slide origin (institution), and scanner type [1]. They trained deep learning models to predict each of these variables.
Not surprisingly, their model was very accurate for slide origin and scanner, but patient age was also highly accurate. The accuracy of slide preparation date predictions varied widely.
In light of these results, they recommended that known batch effect variables should be balanced in the training set. If these easy-to-learn variables are balanced between classes, then the model won’t be able to use them to separate classes. Normalization and preprocessing standardization should also be applied, when appropriate.
Batch Effects in TCGA
Howard et al. studied how batch effects impact deep learning models using the TCGA dataset [2].
Similar to Schmitt et al., they found that deep learning could accurately identify the site that submitted the tissue. This remained true despite the use of color normalization and augmentation techniques.
They further demonstrated that survival times, gene expression patterns, driver mutations, and other variables vary substantially across institutions and should be accounted for during model training. These batch effects can lead to biased estimates of model performance.
Four best practices were highlighted: 1) Variations in model predictions across sites should be reported. 2) If variations across sites are seen, models should not be trained and assessed on patients from the same site. 3) External validation should be the gold standard. 4) In the absence of external validation, they proposed a quadratic programming technique for optimal stratification.
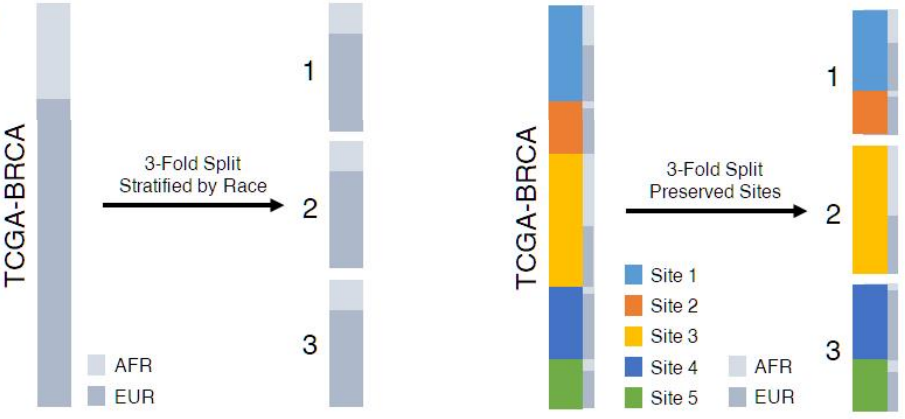
The figure below demonstrates splitting a dataset into three folds, placing each site in a single fold.
Training set splits stratifying by race, irrespective of site (left) versus isolating each site into a single fold (right) [2]
External Validation
Kleppe et al. reviewed the level of validation of existing studies [3]. Five years ago, only a small proportion of studies validated on an external cohort. In 2020, more than 60 percent of the studies they selected performed external validation -- a clear sign of progress!
They also proposed a protocol for external validation of deep learning systems. This protocol involves clearly documenting the model, training data, external cohorts, and analyses.
The training data should include as much natural and artificial variation as possible to improve generalizability. Natural variation includes multiple sets of patients, samples, and data acquisition procedures, while artificial variation refers to data augmentation during model training.
The model should then be validated using a preregistered study protocol that includes description of an external cohort to reduce selection bias and increase transparency.
What are your key challenges in applying machine learning to pathology images?
I'll be writing some new articles reviewing the latest research and want to hit the most relevant topics.
Please reply to this email with any suggestions.
Hope that you’re finding Pathology ML Insights informative. Look out for another edition in two weeks.