Lab Bias, Sensor Bias, and Shortcut Learning
Your AI may look great in the lab — but it might be learning the wrong thing. That gap between the lab and deployment is where vision AI projects stall.
Most vision AI models don’t fail because the math is wrong. They fail because they optimize for what’s easy to learn, not what’s meaningful. This phenomenon has a name: shortcut learning.
When Accuracy Lies
Accuracy scores climb, loss curves flatten, and confidence soars — but hidden shortcuts often drive those results. A cancer classifier might learn pen markings on the slide instead of tumor morphology. A deforestation detector might key on cloud shadows or logging roads instead of canopy loss. A defect detector might flag lighting glare instead of surface damage.
In every case, the model isn’t failing at math — it’s failing at meaning.
The Shortcut Problem
Shortcut learning isn’t a technical bug. It’s an incentive problem. Models chase the easiest predictive cue in the data — and the data doesn’t tell them when they’re wrong.
I’ve seen this across domains. In medical imaging, a model might distinguish hospitals by differences in scanner calibration or tissue stain rather than by detecting the disease itself. Because all hospitals used similar scanners during testing, the validation results looked flawless — but when exposed to new data, the model collapsed in deployment. A model that performs well on biased data doesn’t generalize — it memorizes. For leaders, this means high metrics can disguise high risk. That’s why shortcut learning is so dangerous: it rewards apparent success while hiding real fragility.
Where Bias Hides
Lab Bias: Subtle color, scanner, or staining differences that the model confuses for class features.
Sensor Bias: Resolution, exposure, or spectral variations between devices that alter the signal itself.
Operational Bias: Workflow and labeling differences — who labels, how images are acquired, and which samples are chosen.
These aren’t isolated technical quirks — they’re forms of shortcut learning, where models mistake correlation for causation. And they appear across every industry where visual data drives decisions.
The Real-World Cost
Bias and shortcut learning create a false sense of progress. Teams believe they’re ready for deployment until the model encounters new data and collapses. The damage isn’t just technical — it’s operational. Relabeling and retraining consume months of runway. Stakeholder trust erodes when “AI” can’t explain its decisions. Regulatory or customer approvals stall, delaying adoption.
The cost of shortcut learning isn’t a failed model. It’s the time and confidence lost believing you had a successful one.
How to Spot and Prevent It Vary your data early: Mix labs, sites, sensors, and conditions.
Use site-aware validation: Hold out entire labs, scanners, geographies, or sensors when testing; if performance drops, you’ve likely found a shortcut.
Compare baselines: Simple models can expose when complex ones rely on trivial cues.
Partner with domain experts: They know which patterns are meaningful and which are noise.
Evidence-based iteration saves teams from building beautiful but brittle models.
Closing Thought
A model’s intelligence isn’t in what it predicts — it’s in what it understands.
Book a Pixel Clarity Call to diagnose where shortcut learning might be eroding your model’s reliability — before it costs you time and trust.
- Heather
|
|
 |
Vision AI that bridges research and reality
— delivering where it matters
|
|
|
|
|
|
 |
Blog: Distribution Shift
Disentangling Distribution Shift: The Key to Robust Vision Models
Your model didn’t fail because it was wrong.
It failed because the world changed.
That’s distribution shift—and it breaks even the best models.
A pathology model fails after a scanner upgrade.
A satellite model misfires in monsoon season.
A self-driving car mistakes puddles for potholes.
These shifts often go unnoticed until it’s too late.
Based on dozens of model audits, I’ve seen this pattern again and again. So I put it into a short article.
In it, I break down:
- How shift shows up in real-world healthcare, EO, and wildlife use cases
- Why the most brittle models often looked great in testing
- What leading teams are doing to spot and mitigate shift before it derails deployments
|
|
|
|
|
|
 |
Research: Uncertainty
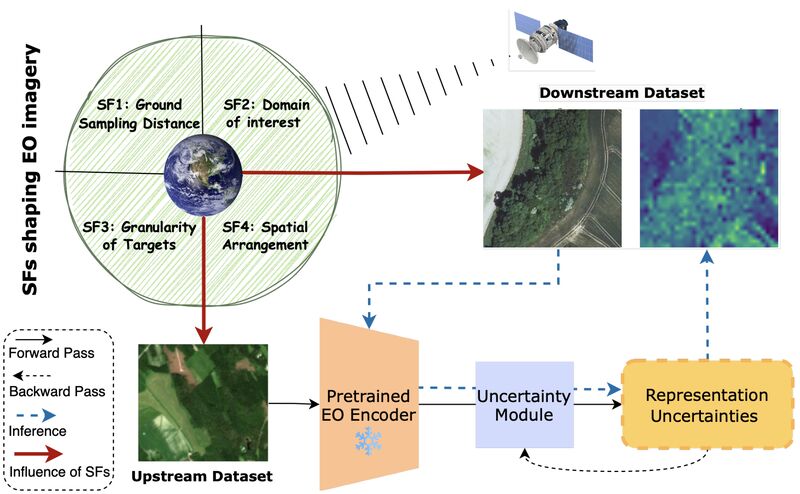
On the Generalization of Representation Uncertainty in Earth Observation
How confident can we be in our EO models' predictions? Spyros Kondylatos et al. investigated whether uncertainty estimation can be learned once and transferred across diverse satellite imagery tasks, addressing a key trustworthiness challenge in remote sensing.
𝗧𝗵𝗲 𝗽𝗿𝗼𝗯𝗹𝗲𝗺: When AI models classify crops for insurance payouts or detect flooding for emergency response, uncertainty matters. A model that's wrong but confident can lead to poor decisions in EO applications.
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀: EO applications require models that can signal when they're
uncertain. Yet standard uncertainty-aware methods introduce increased modeling complexity, high computational overhead, and greater inference demands.
𝗧𝗵𝗲 𝗿𝗲𝘀𝗲𝗮𝗿𝗰𝗵 𝗮𝗽𝗽𝗿𝗼𝗮𝗰𝗵: The team adapted representation uncertainty learning — where uncertainty is extracted directly from pretrained model representations — to EO. They trained uncertainty modules on top of frozen representations to predict task loss as a proxy for uncertainty, then evaluated how well these uncertainties transfer across different EO tasks and datasets.
𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗶𝗼𝗻 𝗶𝗻𝗻𝗼𝘃𝗮𝘁𝗶𝗼𝗻: To systematically study uncertainty generalization, they defined "Semantic Factors" characterizing EO
imagery: ground sampling distance, domain of interest, target granularity, and spatial arrangement. This framework allowed them to analyze how each factor affects uncertainty transfer.
𝗞𝗲𝘆 𝗳𝗶𝗻𝗱𝗶𝗻𝗴𝘀:
• 𝗗𝗼𝗺𝗮𝗶𝗻 𝘀𝗽𝗲𝗰𝗶𝗳𝗶𝗰𝗶𝘁𝘆 𝗺𝗮𝘁𝘁𝗲𝗿𝘀: Major domain gap degrades uncertainty generalization as models pretrained on natural images fail to produce reliable estimations, contrary to EO pretraining
• 𝗦𝘁𝗿𝗼𝗻𝗴 𝘄𝗶𝘁𝗵𝗶𝗻-𝗱𝗼𝗺𝗮𝗶𝗻 𝘁𝗿𝗮𝗻𝘀𝗳𝗲𝗿: EO-pretrained uncertainty generalizes well to unseen
geographic locations, EO tasks, and target granularities
• 𝗥𝗲𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻 𝘀𝗲𝗻𝘀𝗶𝘁𝗶𝘃𝗶𝘁𝘆: Uncertainty generalization is highly sensitive to ground sampling distance, being optimal when the spatial resolutions of pretraining and inference datasets are close
• 𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝘂𝘁𝗶𝗹𝗶𝘁𝘆: Pretrained uncertainties are reliable for zero-shot uncertainty estimation in downstream applications, consistently aligning with task-specific uncertainties
𝗣𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗶𝗺𝗽𝗮𝗰𝘁: The team demonstrated that pretrained uncertainties can identify noisy satellite data and provide
spatial uncertainty estimates out-of-the-box, making uncertainty estimation more accessible for operational EO systems.
Code and models
|
|
|
|
|
|
 |
Research: Deploying FMs
Deploying Geospatial Foundation Models in the Real World: Lessons from WorldCereal
Geospatial foundation models dominate benchmarks, but how many actually make it to production? Christina Butsko et al. delivered the missing playbook for deploying these models in operational systems — and the results from global crop mapping are eye-opening.
𝗧𝗵𝗲 𝗯𝗿𝘂𝘁𝗮𝗹 𝗿𝗲𝗮𝗹𝗶𝘁𝘆: Despite promising benchmark results, the deployment of these models in operational settings is challenging and rare. Standard evaluations miss critical real-world complexities like data heterogeneity, resource constraints, and integration challenges.
𝗧𝗵𝗲
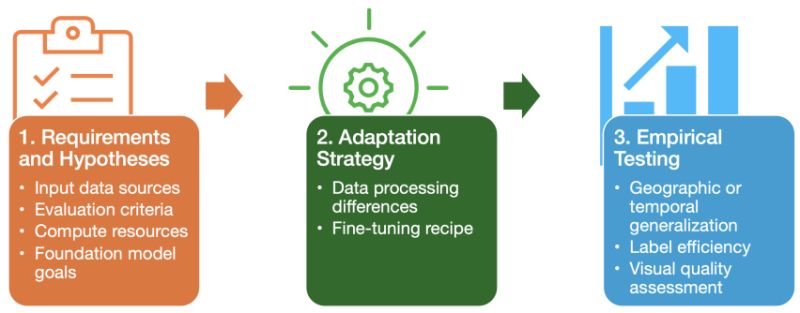
𝘁𝗵𝗿𝗲𝗲-𝘀𝘁𝗲𝗽 𝗱𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁 𝗽𝗿𝗼𝘁𝗼𝗰𝗼𝗹:
Step 1 - Requirements & Hypotheses: Clearly articulate the operational constraints and objectives. Establish which metrics or performance criteria best approximate application success
Step 2 - Adaptation Strategy: Determine what modifications will be needed to adapt the foundation model to the target application
Step 3 - Empirical Testing: Design and execute experiments that simulate real-world scenarios, assessing the model's performance in both standard and challenging conditions
𝗞𝗲𝘆 𝗿𝗲𝗮𝗹-𝘄𝗼𝗿𝗹𝗱 𝗿𝗲𝗮𝗹𝗶𝘁𝗶𝗲𝘀
𝘁𝗵𝗲 𝗽𝗿𝗼𝘁𝗼𝗰𝗼𝗹 𝗮𝗱𝗱𝗿𝗲𝘀𝘀𝗲𝘀:
- Operational systems often lack GPU access
- Data processing differs between pre-training and deployment
- Visual artifacts matter more than accuracy scores for mapping applications
- Geographic and temporal generalization trump benchmark performance
𝗪𝗼𝗿𝗹𝗱𝗖𝗲𝗿𝗲𝗮𝗹 𝗰𝗮𝘀𝗲 𝘀𝘁𝘂𝗱𝘆 𝗿𝗲𝘀𝘂𝗹𝘁𝘀:
Fine-tuning a pre-trained model significantly improves performance over conventional supervised methods, with particularly strong spatial and temporal generalization. The Presto foundation model consistently outperformed baseline approaches across diverse global
regions.
𝗦𝘂𝗿𝗽𝗿𝗶𝘀𝗶𝗻𝗴 𝗶𝗻𝘀𝗶𝗴𝗵𝘁: Additional self-supervised learning rounds didn't improve performance, suggesting that well-aligned foundation models may not need extensive adaptation for related tasks. Although this could be simply because they used the same imagery for fine-tuning.
This research provides practitioners with their first systematic blueprint for moving beyond benchmarks to actual deployment — addressing the operational gap that has limited foundation model adoption.
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Pixel Clarity Call - A free 30-minute conversation to cut through the noise and see where your vision AI project really stands. We’ll pinpoint vulnerabilities, clarify your biggest challenges, and decide if an assessment or diagnostic could save you time, money, and credibility.
Book now
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
