What This Year Quietly Revealed About Computer Vision That Actually Matters
This year, progress in computer vision looked familiar. Bigger models. Faster experimentation. Stronger benchmark results.
And yet, for many teams, something felt off.
A lot of computer vision systems technically worked. Metrics looked solid. Demos were convincing. But once those systems encountered new image sources, different acquisition conditions, or real users making real decisions, confidence started to wobble. Not catastrophically — just enough to slow adoption, trigger manual overrides, or quietly stall promising products.
What stood out wasn’t a lack of modeling expertise. It was how consistently the same kinds of issues showed up across domains. Systems behaved differently when the appearance changed. Validation didn’t fully reflect real operating conditions. Generalization was assumed more broadly than it had actually been tested.
None of this is new. But this year made it harder to ignore.
It became clearer that success in computer vision isn’t just about whether a model performs well on a dataset, but whether the system behaves predictably once images get messy. Reliability started to matter more than peak accuracy. Trust eroded not because errors were frequent, but because their boundaries weren’t well understood.
After years of watching computer vision projects succeed, stall, or fade after launch, I’ve found that a small set of principles consistently explains why. They’re not about architectures or training tricks. They’re about how vision systems are evaluated, deployed, and maintained once the pilot phase ends.
As teams plan for 2026, the most important computer vision decisions won’t be about what to build next — but about what it will take for existing systems to hold up in the real world.
In the new year, I’ll share the framework I use to assess whether computer vision work is genuinely impactful — and why it often points to very different priorities than year-end trend lists.
Happy holidays, and best wishes for the new year.
- Heather
|
|
 |
|
Vision AI that bridges research and reality
— delivering where it matters
|
|
|
|
|
|
 |
Research: Oceans
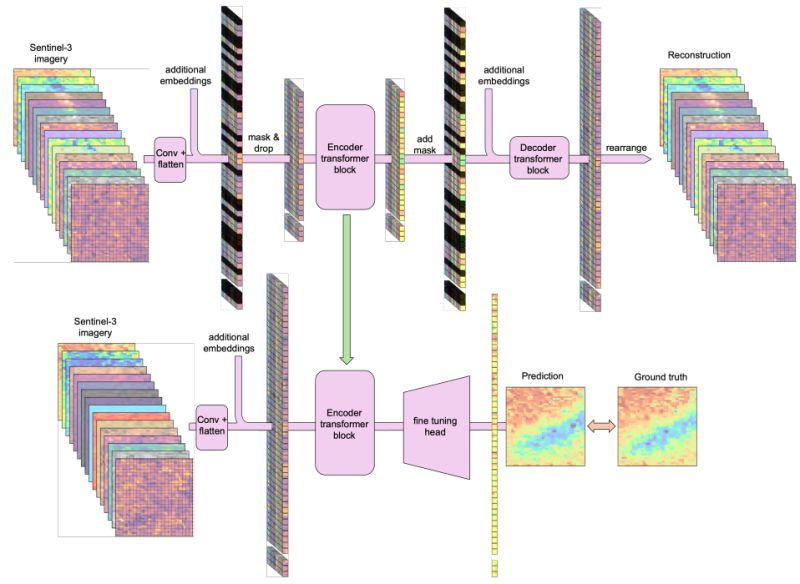
A Sentinel-3 foundation model for ocean colour
Measuring ocean properties directly from ships is expensive, research vessel time is limited, and robotic sensors are scattered sparsely across vast ocean expanses. This is the data scarcity problem that limits marine monitoring.
Remote sensing from satellites like Sentinel-3 provides global coverage, but traditional approaches require substantial labeled data for each downstream task: chlorophyll estimation, primary production modeling, harmful algal bloom detection. When you're working with sparse in-situ validation points scattered across vast ocean regions, building task-specific models becomes inefficient.
Geoffrey Dawson et al. introduce the first foundation model for ocean color, pre-trained on Sentinel-3 OLCI (Ocean and Land Colour Instrument) data using the Prithvi-EO Vision Transformer architecture. The model learns general-purpose representations from massive unlabeled satellite observations, then fine-tunes efficiently on limited labeled data for specific marine applications.
𝗞𝗲𝘆 𝗶𝗻𝗻𝗼𝘃𝗮𝘁𝗶𝗼𝗻𝘀:
- Masked autoencoder pre-training on Sentinel-3 OLCI: 21 spectral bands at 300m resolution, reconstructing randomly masked patches to learn ocean color patterns
- Temporal encoding: Processes multi-temporal image stacks to capture dynamic ocean processes
- Evaluated on two critical tasks: chlorophyll-a concentration estimation and ocean primary production refinement
- Optional integration of sea surface temperature as an additional modality
𝗧𝗵𝗲 𝗿𝗲𝘀𝘂𝗹𝘁𝘀:
The foundation model approach significantly outperforms both random forest baselines and models trained from scratch, demonstrating the value of pre-training on large unlabeled datasets. The model excels at capturing detailed spatial patterns in ocean color while accurately matching sparse point observations from in-situ measurements.
This matters because ocean primary production—the photosynthetic conversion of CO2 to organic carbon by phytoplankton—drives marine food webs and accounts for roughly half of Earth's total primary production. Better estimates from satellite data, validated against limited ship-based measurements, improve our understanding of ocean carbon cycling and ecosystem health.
The approach follows the successful pattern from EO: pre-train once on abundant unlabeled satellite imagery, then adapt efficiently to multiple downstream tasks. For marine science, where ship time costs thousands of dollars per day, and autonomous platforms are still expanding coverage, this data efficiency is essential.
This also highlights a broader trend: domain-specific foundation models often outperform generic models because they're pre-trained on the actual sensor modalities and spatial/temporal patterns relevant to the target domain.
|
|
|
|
|
|
 |
Insights: Pathology
Who Actually Buys Pathology AI?
📌 Aligning with the Stakeholders Who Control Adoption
💡 Adoption isn’t just about model performance—it’s about stakeholder alignment.
The buyer isn’t always the end user—and their priorities differ. 🚫 The person writing the check may never touch the tool.
Pathologists may evaluate accuracy. Lab managers care about throughput. Hospital administrators scrutinize costs and liability. Pharmaceutical collaborators need trial-readiness, biomarker validation, and reproducibility. These priorities can sometimes pull in different directions—but when aligned, they create a powerful case for adoption. Understanding how these stakeholders influence each other—such as lab managers reporting to hospital leadership—helps you design for adoption, not just utility.
Even technically strong tools stall when they only serve one group. Misalignment between stakeholders—like enthusiastic users and skeptical administrators—can break momentum.
It’s easy to focus only on the end user—but real adoption depends on satisfying multiple decision-makers. Real adoption means aligning value across:
🩺 The End-User (Pathologist): trust, transparency, and improved workflow
🧪 The Operator (Lab Manager): efficiency, throughput, and integration
🏥 The Decision-Maker (Hospital Admin/Procurement): ROI, risk mitigation, and compliance
💊 The Strategic Partner (Pharma/Biotech): trial acceleration, patient stratification, and regulatory alignment
Example: Imagine a tool designed for tumor quantification that delivers consistent results in testing—but struggles to gain traction because it doesn’t integrate with LIS (Laboratory Information System) platforms or support the throughput benchmarks lab managers require. With earlier engagement or user-centered design, this misalignment might have been prevented. By contrast, tools that engaged stakeholders early—like AI models for quality control—often gain traction by aligning value across clinical, operational, and financial axes.
Misaligning your value proposition could stall even the most impressive tools.
So what? Failing to align with stakeholders doesn’t just delay adoption—it risks wasted pilots, internal resistance, and budget rejection.
AI adoption isn’t just a product problem—it’s a stakeholder alignment problem. Know who you’re building for and who you’re selling to. Map out each stakeholder’s goals early—then tailor your pitch, pilot, and metrics to speak to what matters most to them.
💬 Which stakeholder do you find hardest to align with—and why?
Leave a comment |
|
|
|
|
|
 |
Research: Agriculture
AgriGPT-VL: Agricultural Vision-Language Understanding Suite
Despite rapid progress in multimodal AI, agricultural applications face three fundamental constraints: lack of domain-tailored models, scarce high-quality vision-language datasets, and inadequate evaluation frameworks.
Bo Yang et al. from Zhejiang University address all three simultaneously with AgriGPT-VL Suite—the most comprehensive agricultural vision-language framework to date.
𝐓𝐡𝐞 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞:
Building effective agricultural VLMs requires massive amounts of paired image-text data with domain expertise. Previous work either synthesized small datasets from vision-only data or relied on limited manual curation. Neither approach scales to the millions of examples needed for robust multimodal reasoning.
𝐓𝐡𝐞 𝐬𝐨𝐥𝐮𝐭𝐢𝐨𝐧—𝐀𝐠𝐫𝐢𝐆𝐏𝐓-𝐕𝐋 𝐒𝐮𝐢𝐭𝐞:
𝟏. 𝐀𝐠𝐫𝐢-𝟑𝐌-𝐕𝐋 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 (largest agricultural VL corpus to date):
- 1M image-caption pairs
- 2M image-grounded VQA pairs
- 50K expert-level VQA instances
- 15K GRPO reinforcement learning samples
Generated by a scalable multi-agent system that combines caption generation, instruction synthesis, multi-agent refinement, and factual filtering—creating a reusable blueprint for scientific domain datasets.
𝟐. 𝐀𝐠𝐫𝐢𝐆𝐏𝐓-𝐕𝐋 𝐌𝐨𝐝𝐞𝐥:
Progressive curriculum training starting:
- Stage 1: Text-only domain grounding to consolidate agricultural knowledge
- Stage 2: Multimodal shallow/deep alignment on synthesized supervision
- Stage 3: GRPO refinement for enhanced reasoning
This approach achieves strong multimodal capabilities while preserving text-only performance—addressing a common failure mode where vision-language training degrades language-only abilities.
𝟑. 𝐀𝐠𝐫𝐢𝐁𝐞𝐧𝐜𝐡-𝐕𝐋-𝟒𝐊:
Comprehensive evaluation with 2,018 open-ended VQA and 1,858 single-choice questions (two per image for cross-validation). Covers recognition, symptom analysis, management recommendations, and multi-step reasoning. Strictly de-duplicated from training data and human-reviewed.
𝐊𝐞𝐲 𝐫𝐞𝐬𝐮𝐥𝐭𝐬:
AgriGPT-VL surpasses most flagship models on agricultural tasks. The multi-agent data generator provides a scalable, transferable approach for building domain-specific VL datasets—potentially applicable beyond agriculture to other scientific domains lacking paired vision-language data.
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬:
This represents a step-change in scale and rigor for agricultural AI: 3M+ training samples (vs. 70K in AgroGPT), comprehensive curriculum training (vs. single-stage tuning), and robust evaluation with 4K diverse test samples. The work demonstrates that with proper infrastructure—scalable data generation, progressive training, and rigorous evaluation—specialized domain models can compete with general-purpose systems.
|
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Pixel Clarity Call - A free 30-minute conversation to cut through the noise and see where your vision AI project really stands. We’ll pinpoint vulnerabilities, clarify your biggest challenges, and decide if an assessment or diagnostic could save you time, money, and credibility.
Book now |
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States |
|
|
|
|
