|
Sustainable AI: Building Systems That Last
There's a pattern in AI deployment that almost everyone in this field has encountered but rarely names directly: the post-launch decay curve. A model ships, accuracy looks good, stakeholders are satisfied—and then quietly, steadily, performance degrades. The data drifts. The team that built the system moves on. Nobody can explain why certain design decisions were made two years ago. The model becomes a black box that everyone is afraid to touch.
Simon Arkell of Ryght calls this the "maintain it on an ongoing basis" problem—one that organizations routinely underestimate until it's too late. Kit Merker of Plainsight frames it differently: model accuracy isn't a destination, it's a forever project. Sustainability in AI means building systems that can survive and improve through the messy, changing conditions of the real world, not just excel in controlled evaluations.
Technical debt starts with data, not code
The conventional image of technical debt is messy code—spaghetti logic, undocumented functions, missing tests. In AI systems, the real debt is usually in the data pipeline. Gard Hauge of StormGeo estimates that 80–85% of the work in successful AI projects is data engineering, not modeling. Ankur Garg of BlocPower describes the upstream challenge of integrating messy, inconsistent data sources—tax assessments versus permits, each with their own formatting quirks—before any predictive work can begin.
The solution isn't better code-cleaning habits; it's an architecture designed for change. Benji Meltzer of Aerobotics builds modular models where a base architecture feeds into context-specific sub-modules calibrated for individual crops, allowing knowledge to transfer from citrus to apples without retraining from scratch. Kit Merker containers AI applications as swappable filters—independent units that can be reconfigured or replaced without disrupting the broader system. They're both avoiding the monolith: a single, opaque model that breaks whenever any input variable shifts.
Drift is also a certainty, not an edge case. Junaid Kalia of NeuroCare.AI has quantified it precisely: their models begin to degrade after approximately 1.5 million images. Their response is a hard refresh cycle, triggered before degradation sets in. Gershom Kutliroff of Taranis faces geographic drift as operations expand into new agricultural regions; their continuous learning framework automatically filters low-confidence field data to retrain and redeploy models before quality slips.
Reproducibility is the unglamorous piece that makes all of this possible. David Healey of Enveda Biosciences warns about path dependency in ML research—teams forget why choices were made, staff turns over, and the reasoning behind the system evaporates. Dave DeCaprio of ClosedLoop argues for versioning the entire pipeline: raw data transformations, feature engineering, post-processing. This isn't just good practice; it's what makes parallel validation possible, where last year's pipeline can run alongside a new version to catch regressions that accuracy metrics alone won't surface.
Operational sustainability means reducing burden, not adding to it
A system that requires constant hand-holding is a failed design. Sean Cassidy of Lucem Health describes the alert fatigue problem directly: clinicians are already overwhelmed with notifications, and an AI that generates a stream of low-confidence flags will simply be ignored—or disabled. Harro Stokman of Kepler Vision targets one false alarm per room per three months in elderly care monitoring. That level of precision isn't a nice-to-have; it's the threshold below which nurses stop trusting the system.
The most effective sustainable AI tends to be invisible. Dirk Smeets of icometrix describes AI as a background service: scans are processed automatically before a radiologist opens the file, so the measurements are already there when they need them. Dean Freestone of Seer distills days of EEG recordings into a curated highlight reel of potential seizures, turning what would otherwise be an impossible review task into something manageable. The model's job is to reduce the work, not to introduce a new layer of complexity the user must navigate.
Economic sustainability requires honest cost of ownership accounting
The build cost is almost never the biggest cost. Infrastructure, compute, retraining cycles, data acquisition, quality control at scale—these are what determine whether a project survives its first year in production.
Ranveer Chandra of Microsoft Research makes the optimization logic explicit: continuously processing high-resolution satellite data may not be economically viable. Systems should process data only when changes occur, keeping unit costs aligned with value delivered. David Sontag of Layer Health notes that once a model performs well, the engineering challenge shifts entirely to making it cheap enough to run at scale.
Vendor dependency is an underappreciated risk. Simon Arkell describes the technical debt that accumulates around a single proprietary model: if that model becomes obsolete, the entire system needs rebuilding. His approach at Ryght is to abstract the model layer so components can be swapped as better options emerge. Paul Hérent of Raidium argues that proprietary data—not model architecture—is the real competitive moat, because data is what enables retraining or architectural changes without losing ground.
Right-sizing models for environmental responsibility
AI systems have their own environmental costs—data center energy consumption isn't abstract. Mathieu Bauchy of Concrete.ai is direct about it: developers need to ensure that training and running their models doesn't consume more resources than the problems they're solving.
The practical response is to resist the pull toward larger architectures when smaller, specialized ones perform better. Dmitry Nechaev of HistAI chose a 300-million parameter model over billion-plus alternatives because it runs an order of magnitude faster while maintaining quality—a decision with direct implications for inference costs and energy use. Bruno Sánchez-Andrade Nuño of Clay makes the case for foundation models as an environmental asset: the expensive pretraining happens once, and downstream users fine-tune for specific tasks at a fraction of the cost of training from scratch.
Greg Mulholland of Citrine Informatics puts it plainly: customer value over AI flash, every single day. The newest architecture isn't the right architecture just because it's new.
Sustainability as a design requirement
The systems worth building are the ones still running and improving five years after launch—accurate enough to trust, efficient enough to afford, and designed so that the team maintaining them in 2030 can understand the decisions made in 2025. That's not a constraint on ambition. It's what makes the work count.
- Heather
|
|
 |
|
Vision AI that bridges research and reality
— delivering where it matters
|
|
|
|
|
|
 |
Research: Clinical Copilots
From Encoders to Copilots: The Next Generation of Pathology AI
For the last two years, the field has focused on building better tile feature extractors. But three new papers signal a shift toward clinical copilots: models that don't just see morphology, but write reports, answer questions, and function across the entire slide at once.
Here is how the latest research compares:
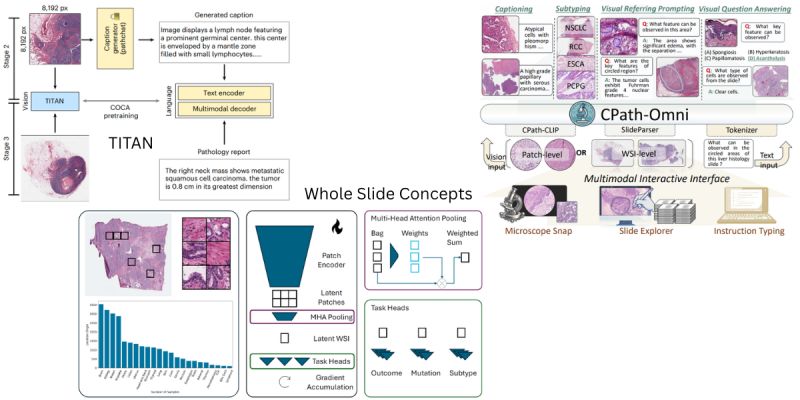
The "Train Short, Test Long" Approach: Tong Ding et al. introduce TITAN, a foundation model designed to solve the context problem. While standard Transformers struggle with gigapixel slides, TITAN employs a "train short, test long" strategy using ALiBi positional encoding. It learns on 8k×8k regions but extrapolates to the whole slide at inference. Crucially, it utilizes a tri-stage pretraining recipe: starting with vision-only distillation, moving to alignment with synthetic fine-grained captions (generated by a copilot), and finishing with real-world clinical reports. This allows TITAN to generate diagnostic reports and retrieve rare cancer cases zero-shot.
Unifying the Patch and the Slide: Yuxuan Sun et al. argue that treating patch and slide analysis as separate tasks creates redundancy. They present CPath-Omni, a 15B parameter Large Multimodal Model. This is the first model to unify tasks at both levels—classification, Visual Question Answering, and captioning—into a single architecture. By integrating a specialized visual processor (CPath-CLIP), it achieves state-of-the-art performance on 39 out of 42 diverse datasets, effectively acting as a general-purpose vision-language assistant.
The Efficiency Counter-Argument: While the models above rely on massive self-supervised pretraining, Till Nicke et al. challenge the "scale is all you need" dogma. They introduce Whole Slide Concepts, a supervised foundation model. They argue that expensive self-supervision is unnecessary when patient-level labels (diagnosis, risk, mutations) are free byproducts of clinical care. By using end-to-end multitask learning, their model outperforms self-supervised competitors on seven benchmarks while requiring only 5% of the computational resources, proving that clinical labels may be a more efficient signal than raw pixel scaling.
The takeaway: A divergence in strategy. TITAN and CPath-Omni are betting on generative, multimodal flexibility to handle complex queries. Whole Slide Concepts is betting on extreme efficiency through direct clinical supervision.
|
|
|
|
|
|
 |
Research: Technical Variations
Impact of tissue staining and scanner variation on the performance of pathology foundation models: a study of sarcomas and their mimics
Pathology foundation models often look highly accurate during internal testing, but moving them into a real-world clinic introduces a major variable: different hospitals use wildly different staining protocols and slide scanners.
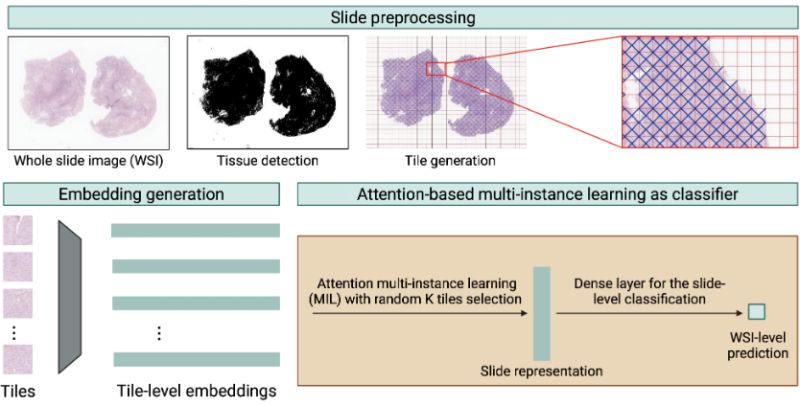
To evaluate if modern AI is truly ready for clinical deployment, Binghao Chai et al.stress-tested seven models on a challenging proxy task: classifying 14 types of soft tissue tumours (sarcomas and their mimics).
Here are the key findings from their rigorous multi-institutional study:
• 𝗦𝗹𝗶𝗱𝗲 𝘃𝘀. 𝗣𝗮𝘁𝗰𝗵 𝗘𝗻𝗰𝗼𝗱𝗲𝗿𝘀: The authors found an interesting trade-off regarding data efficiency. Slide-level encoders like 𝗧𝗜𝗧𝗔𝗡 showed strong discriminative power even with very few examples. However, as the "training set size increased, patch-based encoders showed rapid performance gains, suggesting that while slide encoders excel in low-data regimes, patch encoders may match or surpass them when data are abundant."
• 𝗧𝗵𝗲 𝗣𝗼𝘄𝗲𝗿 𝗼𝗳 𝗗𝗶𝘃𝗲𝗿𝘀𝗲 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝙜: Even the best foundation models experienced an accuracy drop when tested on slides from outside institutions. But there is a straightforward, data-efficient fix: including just a small subset of externally stained slides in the training phase significantly closed this performance gap and improved overall generalizability.
• 𝗔 𝗠𝗮𝘀𝘀𝗶𝘃𝗲 𝗢𝗽𝗲𝗻 𝗗𝗮𝘁𝗮𝘀𝗲𝘁: To help the field overcome these exact domain generalization challenges, the team is making their benchmark public. As they note, "we are releasing a unique multi-institutional dataset comprising over 1,200 whole slide images covering 14 tumour types, stained in 30 institutions, and scanned with three scanners."
𝗧𝗵𝗲 𝗧𝗮𝗸𝗲𝗮𝘄𝗮𝘆: While foundation models are far more resilient than traditional models, they still struggle with scanner and stain variations out-of-the-box. The path forward involves deliberately injecting multi-institutional diversity into training pipelines to ensure true clinical reliability.
|
|
|
|
|
|
 |
Research: Efficiency
Distilling foundation models for robust and efficient models in digital pathology
𝘛𝘩𝘦 𝘢𝘥𝘷𝘦𝘯𝘵 𝘰𝘧 𝘧𝘰𝘶𝘯𝘥𝘢𝘵𝘪𝘰𝘯 𝘮𝘰𝘥𝘦𝘭𝘴 𝘪𝘯 𝘥𝘪𝘨𝘪𝘵𝘢𝘭 𝘱𝘢𝘵𝘩𝘰𝘭𝘰𝘨𝘺 𝘩𝘢𝘴 𝘳𝘦𝘭𝘪𝘦𝘥 𝘩𝘦𝘢𝘷𝘪𝘭𝘺 𝘰𝘯 𝘴𝘤𝘢𝘭𝘪𝘯𝘨—𝘣𝘪𝘨𝘨𝘦𝘳 𝘥𝘢𝘵𝘢𝘴𝘦𝘵𝘴, 𝘭𝘢𝘳𝘨𝘦𝘳 𝘮𝘰𝘥𝘦𝘭𝘴, 𝘢𝘯𝘥 𝘮𝘢𝘴𝘴𝘪𝘷𝘦 𝘤𝘰𝘮𝘱𝘶𝘵𝘦. 𝘉𝘶𝘵 𝘥𝘰𝘦𝘴 𝘤𝘭𝘪𝘯𝘪𝘤𝘢𝘭 𝘥𝘦𝘱𝘭𝘰𝘺𝘮𝘦𝘯𝘵 𝘢𝘭𝘸𝘢𝘺𝘴 𝘳𝘦𝘲𝘶𝘪𝘳𝘦 𝘢 𝘨𝘪𝘢𝘯𝘵?
While scaling has significantly improved performance across diverse downstream tasks, it has also introduced steep computational costs and slower inference times. For AI to be widely adopted in real-world clinical workflows, models must be fast, cost-effective, and deeply robust to the hardware variability seen across different hospitals.
A new preprint by Alexandre Filiot et al. explores a powerful solution to this deployment bottleneck: model distillation.
Here are the key takeaways from their research:
• 𝗧𝗵𝗲 𝗛𝟬-𝗺𝗶𝗻𝗶 𝗠𝗼𝗱𝗲𝗹: The research team successfully distilled a massive foundation model into a much smaller architecture. This lightweight model, named 𝗛𝟬-𝗺𝗶𝗻𝗶, reduces the number of parameters by several orders of magnitude, which drastically cuts down on inference costs.
• 𝗖𝗼𝗺𝗽𝗲𝘁𝗶𝘁𝗶𝘃𝗲 𝗣𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲: Efficiency does not have to mean a massive drop in accuracy. 𝗛𝟬-𝗺𝗶𝗻𝗶 achieved nearly comparable performance to large foundation models, securing 3rd place on the 𝗛𝗘𝗦𝗧 benchmark and 5th place on the 𝗘𝗩𝗔 benchmark.
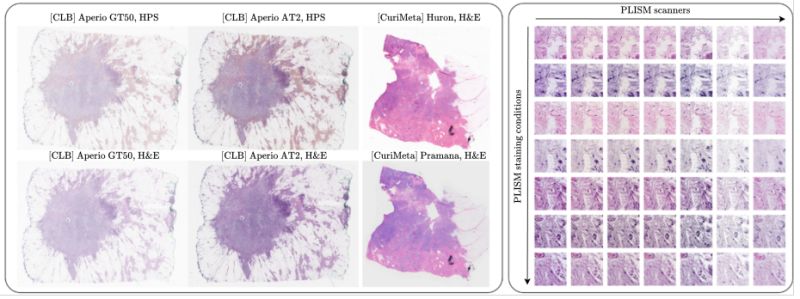
• 𝗦𝘂𝗽𝗲𝗿𝗶𝗼𝗿 𝗥𝗼𝗯𝘂𝘀𝘁𝗻𝗲𝘀𝘀: Bigger models aren't always more resilient to real-world noise. When evaluated on the 𝗣𝗟𝗜𝗦𝗠 dataset, 𝗛𝟬-𝗺𝗶𝗻𝗶 demonstrated excellent robustness to variations in staining and scanning conditions. In fact, it significantly outperformed other state-of-the-art models in handling these common clinical domain shifts.
𝗧𝗵𝗲 𝗧𝗮𝗸𝗲𝗮𝘄𝗮𝘆: The future of clinical pathology AI requires a balance of power and practicality. Distillation opens new perspectives to design lightweight, highly robust models without compromising on essential diagnostic performance.
|
|
|
|
|
|
 |
Research: Efficiency
A Deployment-Friendly Foundational Framework for Efficient Computational Pathology
Pathology foundation models have revolutionized computational pathology, but their massive size creates a deployment bottleneck. Processing gigapixel whole slide images with these models is computationally expensive, limiting their accessibility and scalability in real-world clinical settings.
A new preprint by 𝙔𝙪 𝘾𝙖𝙞 𝙚𝙩 𝙖𝙡. addresses this barrier directly, introducing 𝙇𝙞𝙩𝙚𝙋𝙖𝙩𝙝, a deployment-friendly framework designed to make clinical AI fast, cost-effective, and viable on low-power hardware.
Here are the key innovations from their research:
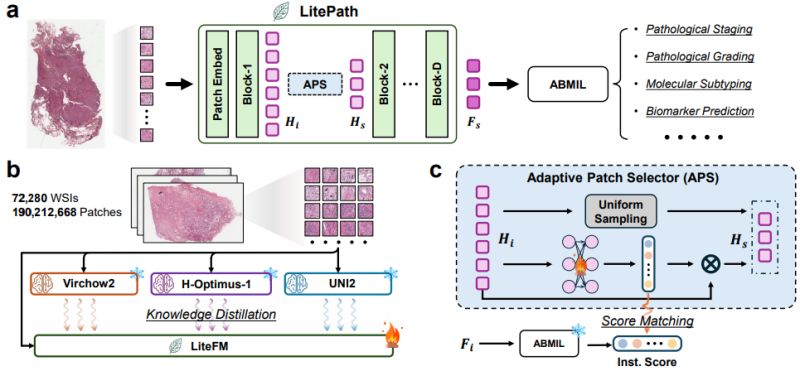
• 𝙏𝙝𝙚 𝙇𝙞𝙩𝙚𝙁𝙈 𝙈𝙤𝙙𝙚𝙡: Instead of building another massive model from scratch, the team distilled knowledge from three industry-leading FMs (Virchow2, H-Optimus-1, and UNI2) into a highly compact model using 190 million patches.
• 𝘼𝙙𝙖𝙥𝙩𝙞𝙫𝙚 𝙋𝙖𝙩𝙘𝙝 𝙎𝙚𝙡𝙚𝙘𝙩𝙤𝙧 (𝘼𝙋𝙎): To mitigate patch-level redundancy, the framework incorporates a lightweight component that actively selects only the most relevant patches for specific diagnostic tasks, drastically reducing computational waste.
• 𝙀𝙙𝙜𝙚-𝙍𝙚𝙖𝙙𝙮 𝙀𝙛𝙛𝙞𝙘𝙞𝙚𝙣𝙘𝙮: The practical results are striking. Compared to Virchow2, 𝙇𝙞𝙩𝙚𝙋𝙖𝙩𝙝 reduces parameters by 28x and lowers FLOPs by 403.5x. It can run entirely on a low-power edge device (the NVIDIA Jetson Orin Nano Super), where it processes 208 slides per hour (104.5x faster) and consumes 171x less energy than Virchow2 running on an RTX3090 GPU.
• 𝙏𝙝𝙚 𝘿𝙚𝙥𝙡𝙤𝙮𝙖𝙗𝙞𝙡𝙞𝙩𝙮 𝙎𝙘𝙤𝙧𝙚: To properly quantify the trade-off between diagnostic accuracy and computational cost, the authors propose a new metric combining normalized AUC and FLOPs. Evaluated across 37 cohorts and 26 diverse tasks, 𝙇𝙞𝙩𝙚𝙋𝙖𝙩𝙝 achieves the highest 𝘿-𝙎𝙘𝙤𝙧𝙚 among 19 evaluated models.
𝙏𝙝𝙚 𝙏𝙖𝙠𝙚𝙖𝙬𝙖𝙮: While massive models continue to push the boundaries of what is possible, model distillation and smart patch selection push the boundaries of what is practical. 𝙇𝙞𝙩𝙚𝙋𝙖𝙩𝙝 proves that we can maintain 99.71% of state-of-the-art accuracy while running on accessible, energy-efficient hardware—significantly reducing both the cost and the carbon footprint of AI deployment.
TITAN
CPath-Omni
Whole Slide Concepts
|
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Pixel Clarity Call - A free 30-minute conversation to cut through the noise and see where your vision AI project really stands. We’ll pinpoint vulnerabilities, clarify your biggest challenges, and decide if an assessment or diagnostic could save you time, money, and credibility.
Book now |
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States |
|
|
|
|
