 |
Insights: EO Embeddings
What Do Embeddings Actually Encode in Earth Observation Foundation Models
Foundation models are reshaping how we analyze satellite imagery—but what exactly do their embeddings capture?
These seemingly simple vectors power land cover maps, similarity search, and plug-and-play use in downstream models. But depending on how they’re trained, 𝐭𝐡𝐞𝐲 𝗺𝗮𝘆 𝗲𝗻𝗰𝗼𝗱𝗲 𝘁𝗵𝗲 𝘄𝗿𝗼𝗻𝗴 𝗸𝗶𝗻𝗱𝘀 𝗼𝗳 𝘀𝗶𝗺𝗶𝗹𝗮𝗿𝗶𝘁𝘆.
An embedding might be just a few hundred numbers, but 𝘄𝗵𝗮𝘁 those numbers encode can vary
wildly based on:
- Pretraining objectives (e.g., contrastive learning, masked image modeling)
- Architecture and inductive biases (e.g., CNNs vs transformers)
- Data sampling choices: where, when, how often
This matters because in EO, 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝘀𝗶𝗺𝗶𝗹𝗮𝗿𝗶𝘁𝘆 𝗱𝗼𝗲𝘀𝗻’𝘁 𝗮𝗹𝘄𝗮𝘆𝘀 𝗮𝗹𝗶𝗴𝗻 𝘄𝗶𝘁𝗵 𝘃𝗶𝘀𝘂𝗮𝗹 𝘀𝗶𝗺𝗶𝗹𝗮𝗿𝗶𝘁𝘆. And 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝘀𝗶𝗺𝗶𝗹𝗮𝗿𝗶𝘁𝘆 𝗰𝗮𝗻
𝗲𝘃𝗲𝗻 𝗱𝗲𝗽𝗲𝗻𝗱 𝗼𝗻 𝘁𝗵𝗲 𝗰𝗼𝗻𝘁𝗲𝘅𝘁 𝗮𝗻𝗱 𝘆𝗼𝘂𝗿 𝗴𝗼𝗮𝗹𝘀.
🔍 Should a deciduous forest in Canada be close in embedding space to one in Brazil?
🌐 Should two desert regions differ based on soil moisture, elevation, or something else entirely?
For example, if you're building a wildfire risk model, you might want forests with similar burn behavior—regardless of their species or appearance—to cluster together. But for a biodiversity application, taxonomic similarity might matter more.
𝗪𝗵𝗮𝘁 𝗰𝗼𝘂𝗻𝘁𝘀 𝗮𝘀 “𝘀𝗶𝗺𝗶𝗹𝗮𝗿”
𝗶𝗻 𝗼𝗻𝗲 𝗘𝗢 𝘁𝗮𝘀𝗸 𝗺𝗮𝘆 𝗯𝗲 𝗺𝗶𝘀𝗹𝗲𝗮𝗱𝗶𝗻𝗴 𝗶𝗻 𝗮𝗻𝗼𝘁𝗵𝗲𝗿. Embeddings that group images by vegetation color, for instance, might help with land classification—but fail for models assessing wildfire risk.
𝗜𝗳 𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 𝗰𝗹𝘂𝘀𝘁𝗲𝗿 𝘁𝗼𝗼 𝘁𝗶𝗴𝗵𝘁𝗹𝘆 𝗯𝘆 𝗴𝗲𝗼𝗴𝗿𝗮𝗽𝗵𝘆, we risk conflating 𝗹𝗼𝗰𝗮𝘁𝗶𝗼𝗻 with 𝗹𝗮𝗻𝗱
𝗰𝗼𝘃𝗲𝗿. If they embed trivial signals like elevation or sun angle, we may be capturing 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮, not 𝗺𝗲𝗮𝗻𝗶𝗻𝗴.
💡 Instead, we should design embedding models that:
- Emphasize semantically meaningful distinctions (e.g., cropland vs pasture)
- Suppress redundant or easily modeled signals (e.g., latitude)
- Reflect intended downstream tasks (retrieval ≠ segmentation ≠ classification)
𝗔𝘀 𝘄𝗲 𝗮𝗱𝗼𝗽𝘁 𝗳𝗼𝘂𝗻𝗱𝗮𝘁𝗶𝗼𝗻 𝗺𝗼𝗱𝗲𝗹𝘀, 𝘄𝗲 𝗰𝗮𝗻’𝘁 𝘁𝗿𝗲𝗮𝘁
𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 𝗮𝘀 𝗯𝗹𝗮𝗰𝗸 𝗯𝗼𝘅𝗲𝘀. Their structure shapes how knowledge travels through EO pipelines—and where it gets lost or distorted.
👇 𝗪𝗵𝗮𝘁’𝘀 𝘆𝗼𝘂𝗿 𝘁𝗮𝗸𝗲: 𝗪𝗵𝗮𝘁 𝘀𝗵𝗼𝘂𝗹𝗱 “𝘀𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝘀𝗶𝗺𝗶𝗹𝗮𝗿𝗶𝘁𝘆” 𝗺𝗲𝗮𝗻 𝗶𝗻 𝗘𝗮𝗿𝘁𝗵 𝗢𝗯𝘀𝗲𝗿𝘃𝗮𝘁𝗶𝗼𝗻
𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀?
Leave a comment
|
|
|
|
|
|
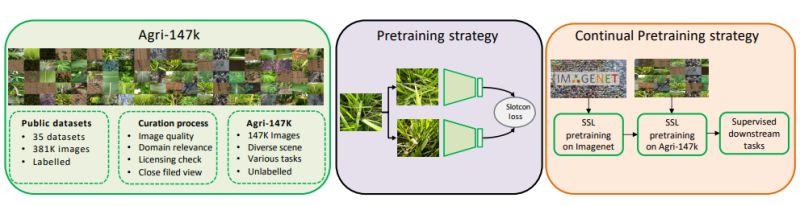 |
Research: Foundation Model for Agriculture
Agri-FM+: A Self-Supervised Foundation Model for Agricultural Vision
General-purpose vision models trained on natural images struggle with agricultural tasks. Farm imagery differs fundamentally from typical computer vision datasets.
Md Jaber Al Nahian et al. introduce Agri-FM+, the first self-supervised foundation model specifically designed for close-field agricultural vision tasks.
𝗪𝗵𝘆 𝗔𝗴𝗿𝗶𝗰𝘂𝗹𝘁𝘂𝗿𝗮𝗹 𝗩𝗶𝘀𝗶𝗼𝗻 𝗡𝗲𝗲𝗱𝘀 𝗗𝗼𝗺𝗮𝗶𝗻-𝗦𝗽𝗲𝗰𝗶𝗳𝗶𝗰
𝗠𝗼𝗱𝗲𝗹𝘀:
Agricultural images present unique challenges that differentiate them from natural image datasets:
• 𝗦𝗺𝗮𝗹𝗹, 𝗱𝗲𝗻𝘀𝗲 𝗼𝗯𝗷𝗲𝗰𝘁𝘀: Individual plants, fruits, and disease symptoms are often tiny and closely packed together
• 𝗦𝘂𝗯𝘁𝗹𝗲 𝘃𝗶𝘀𝘂𝗮𝗹 𝗱𝗶𝗳𝗳𝗲𝗿𝗲𝗻𝗰𝗲𝘀: Critical for tasks like disease detection, pest identification, and crop phenotyping that require fine-grained analysis
• 𝗘𝗻𝘃𝗶𝗿𝗼𝗻𝗺𝗲𝗻𝘁𝗮𝗹 𝘃𝗮𝗿𝗶𝗮𝗯𝗶𝗹𝗶𝘁𝘆:
Significant changes in lighting, growth stages, and field conditions create challenging heterogeneity
• 𝗟𝗶𝗺𝗶𝘁𝗲𝗱 𝗹𝗮𝗯𝗲𝗹𝗲𝗱 𝗱𝗮𝘁𝗮: Agricultural annotation is expensive and time-intensive
𝗧𝗵𝗲 𝗔𝗽𝗽𝗿𝗼𝗮𝗰𝗵:
The researchers developed Agri-FM+ using a two-stage continual learning pipeline:
• 𝗖𝘂𝗿𝗮𝘁𝗲𝗱 𝗔𝗴𝗿𝗶-𝟭𝟰𝟳𝗞 𝗱𝗮𝘁𝗮𝘀𝗲𝘁: High-quality agricultural images systematically selected from 35 public datasets, filtered for domain relevance and visual fidelity
• 𝗖𝗼𝗻𝘁𝗶𝗻𝘂𝗮𝗹
𝗽𝗿𝗲𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴: First learns general features from ImageNet, then adapts to agricultural-specific data
• 𝗦𝗲𝗹𝗳-𝘀𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗲𝗱 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴: Eliminates dependence on manual annotations while learning structured representations
𝗞𝗲𝘆 𝗥𝗲𝘀𝘂𝗹𝘁𝘀:
Evaluated across eight diverse agricultural benchmarks covering object detection, semantic segmentation, and instance segmentation:
• +1.27% average improvement over supervised ImageNet pretraining under full supervision
• +8.25% average gain over random initialization
• Strong performance even with limited data: +1.02% over ImageNet with only 10% labeled examples
•
Consistent improvements across tasks from wheat head detection to plant disease segmentation
𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀 𝗶𝗻 𝗣𝗿𝗲𝗰𝗶𝘀𝗶𝗼𝗻 𝗔𝗴𝗿𝗶𝗰𝘂𝗹𝘁𝘂𝗿𝗲:
This work enables more accurate and efficient computer vision for:
• Crop monitoring and yield estimation
• Plant disease identification and early detection
• Pest management and identification
• Automated agricultural robotics and machinery
• Precision farming applications
The model code and weights will be made publicly available (although they're not up yet).
|
|
|
|
|
|
 |
Insights: Shortcuts
Shortcut Learning in Histopathology Models
Your model might be learning site-specific quirks—not cancer morphology.
𝐖𝐡𝐞𝐧 𝐘𝐨𝐮𝐫 𝐌𝐨𝐝𝐞𝐥 𝐋𝐞𝐚𝐫𝐧𝐬 𝐭𝐡𝐞 𝐖𝐫𝐨𝐧𝐠 𝐋𝐞𝐬𝐬𝐨𝐧 𝐟𝐫𝐨𝐦 𝐘𝐨𝐮𝐫 𝐃𝐚𝐭𝐚
Your model may show high validation accuracy—but what is it actually learning?
🧪 Imagine training a model to classify tumor grade in breast cancer. The model performs well during development—but unknown to the developers, it has
learned to associate thinner tissue sections with low-grade tumors. Thinner cuts offer crisper nuclear detail, while thicker sections not only blur boundaries but also tend to stain darker—introducing another visual difference unrelated to biology. If section thickness varies across labs, the model may end up associating tissue thickness with the most common tumor grade seen at each site—leading to predictions driven by lab-specific artifacts rather than pathology.
That’s the danger of shortcut learning: your model looks smart in the lab, but it’s clueless in the clinic.
You can catch these problems early with techniques like saliency maps, controlled perturbation tests, or external validation from diverse labs.
𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲: If you don’t uncover shortcut learning during development, your model is likely to fail silently in the clinic.
📣 Your turn: Have you ever
caught a model learning the wrong thing?
Leave a comment
|
|
|
|
|
|
 |
Insights: Sustainability
AI's Carbon Footprint Mystery
As a computer vision scientist, I've been thinking about something uncomfortable: many of the architectural decisions that determine carbon footprint are no longer in our hands. We're 2-3 years into the foundation model era, yet we're still largely guessing about the environmental impact of the models we build on top of.
When I submit a request to OpenAI or Anthropic, there's an invisible web of energy consumption completely outside my control. I can optimize my prompts and reduce token usage, but I can't choose whether the model uses attention mechanisms efficiently, or whether it's running on renewable energy. The fundamental architectural decisions - ResNet vs. ViT, model compression, quantization strategies - were made by foundation
model teams I'll never influence.
𝗧𝗵𝗲 𝗦𝗰𝗮𝗹𝗲 𝗪𝗲'𝗿𝗲 𝗕𝘂𝗶𝗹𝗱𝗶𝗻𝗴 𝗢𝗻:
- A single API call to GPT-4 uses orders of magnitude more energy than the lightweight vision models I could build from scratch
- My research now depends on vision transformers where the massive training carbon cost was paid upfront by tech giants and amortized across millions of downstream applications
- The computer vision community has largely shifted from training custom architectures to fine-tuning or prompting massive pre-trained models
𝗪𝗵𝗲𝗿𝗲 𝗢𝘂𝗿 𝗔𝗴𝗲𝗻𝗰𝘆 𝗪𝗲𝗻𝘁:
Ten years ago, I chose between CNN architectures, designed custom networks, and controlled every
parameter. Now I choose between foundation model providers. The most impactful efficiency decisions - model architecture, training strategies, data center locations, energy sources - happen at companies with billion-dollar infrastructure budgets, not in academic labs.
𝗪𝗵𝗮𝘁 𝗪𝗲 𝗖𝗮𝗻 𝗦𝘁𝗶𝗹𝗹 𝗗𝗼:
- Choose smaller, more efficient foundation models when they meet our accuracy needs
- Advocate for energy transparency from foundation model providers
- Develop techniques that minimize inference calls and token usage
- Support open-source alternatives that publish their carbon footprints
- Push for standardized environmental impact reporting in model documentation
The irony is that as individual researchers, we're more dependent on others' efficiency choices than ever, yet the scale of impact has never been
higher.
How do you navigate the tension between using powerful foundation models and environmental responsibility?
Inspired by Wired's article on the growing energy use of AI:
How Much Energy Does AI Use? The People Who Know Aren’t Saying
|
|
|
|
|
|
 |
Blog: CV Pitfalls
Avoid These 3 Pitfalls That Quietly Derail Computer Vision Projects
Text🚨 𝗬𝗼𝘂𝗿 𝗺𝗲𝘁𝗿𝗶𝗰𝘀 𝗹𝗼𝗼𝗸 𝗴𝗿𝗲𝗮𝘁—𝘂𝗻𝘁𝗶𝗹 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗵𝗶𝘁𝘀 𝘁𝗵𝗲 𝗿𝗲𝗮𝗹 𝘄𝗼𝗿𝗹𝗱. Then it fails—quietly, and expensively.
I've seen teams lose months of progress—not because their model was wrong, but because their 𝘥𝘢𝘵𝘢 𝘴𝘦𝘵𝘶𝘱 was.
The patterns are surprisingly consistent.
Auditing CV projects across pathology, life science, and the environment, I keep seeing the same 3 hidden pitfalls:
- Noisy or inconsistent labels
- Skipping baselines (so you're flying blind)
- Data leakage that makes metrics look great—until deployment
These aren't engineering bugs. They're 𝗽𝗿𝗼𝗰𝗲𝘀𝘀 𝗳𝗮𝗶𝗹𝘂𝗿𝗲𝘀—and they quietly erode real-world performance, even when the metrics look great.
🧠 I unpack the 3 most common failure patterns—and how to spot them 𝘣𝘦𝘧𝘰𝘳𝘦 𝘵𝘩𝘦𝘺 𝘲𝘶𝘪𝘦𝘵𝘭𝘺 𝘥𝘦𝘳𝘢𝘪𝘭 𝘺𝘰𝘶𝘳 𝘯𝘦𝘹𝘵
𝘮𝘪𝘭𝘦𝘴𝘵𝘰𝘯𝘦.
If you lead a CV team—or invest in one—this could save you months of wasted effort.
💬 What's the most unexpected way a model has failed you in the wild?
Leave a comment
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Office Hours -- Are you a student with questions about machine learning for pathology or remote sensing? Do you need career advice? Once a month, I'm available to chat about your research, industry trends, career opportunities, or other topics.
Register for the next session
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
