How to Benchmark a Foundation Model for Your Domain
Whether you’re evaluating what’s on the market—or developing your own.
Foundation models are increasingly presented as universal solutions for computer vision: adaptable to any task, robust across any setting, ready to deploy with minimal tuning. But anyone working in a specialized domain knows that real-world data rarely behaves the way these models expect. A model pretrained on millions of images may still buckle under your stain chemistry, your scanner, your phenotype distribution, or your geography.
This is where benchmarking becomes essential. And not only when comparing vendors. A well-designed benchmark is equally important when you’re building or adapting a domain-specific foundation model internally. In both scenarios, the real question is the same: Is this model fit for your tasks, your data distributions, and your operational constraints?
Start With the Problem—Not the Model
Every strong benchmark begins with a clear understanding of the decision the model will ultimately influence. Before thinking about architectures or embeddings, teams need to articulate what success looks like in context. Will the model triage slides, detect anomalies, quantify disease severity, monitor crop stress, or map land cover? And what does “good enough” performance actually mean? A small performance drop might be acceptable for early-stage research, but entirely unacceptable for a workflow tied to patient safety or regulatory documentation.
This grounding is equally critical when evaluating external FMs or refining your own internal candidates. Without it, teams end up measuring what is convenient, not what matters.
Benchmark Against the Distribution Shifts That Actually Define Your Domain
Model failures in the real world almost always arise from unseen variability—distribution shift. The specific shifts that matter vary by domain. In pathology, they include lab-to-lab variation, stain chemistry drift, scanner differences, tissue preparation nuances, and cohort diversity. In Earth observation, agriculture, and forestry, they show up as changes in geography, weather, phenology, seasonality, sensor type, and atmospheric conditions.
A meaningful benchmark incorporates all of these. Evaluating only on in-distribution data gives a false sense of confidence. Instead, test the model on three slices:
-
in-distribution data the model was trained or adapted on,
-
near out-of-distribution data that reflects everyday variability, and
-
far out-of-distribution data that mimics rare but consequential extremes.
This structure allows you to map not just performance, but stability—a critical trait for any model meant to operate beyond controlled environments.
Focus on the Four Pillars That Determine Deployability
While many evaluation frameworks emphasize long lists of attributes, only four consistently shape whether a foundation model is usable in practice:
-
Accuracy captures the model’s raw ability to perform your tasks.
-
Robustness assesses whether that performance holds under your actual distribution shifts.
-
Scalability includes memory limits, inference cost, and the ability to process data at the volume and speed your workflow requires.
-
Reliability captures how predictable the model is—how gracefully it fails, how often it surprises you, and whether its outputs integrate cleanly into your QC processes.
These pillars matter whether you’re choosing a model or building your own.
Benchmark the Full Workflow, Not Just the Model
A foundation model’s value is mediated through the pipeline that surrounds it. Preprocessing choices, tiling strategies, prompting or adapter methods, downstream classifiers, post-processing rules, and human-in-the-loop review all influence real-world effectiveness. Latency and memory constraints can quietly undermine even the most elegant model. That’s why benchmarking needs to occur within the workflow where the model will live—not in a standalone evaluation script detached from operational reality.
Build a Benchmark Suite Designed for Your Company’s Needs
A practical benchmarking suite includes three components that work together to reveal a model’s true strengths and weaknesses:
-
Representative sample tasks — a small set of real tasks your team performs today, such as tissue classification, segmentation, biomarker prediction, crop stress detection, or land-cover mapping. These create continuity across evaluation cycles, whether you’re comparing external FMs or iterating on internal models.
-
Curated distribution shift sets — deliberately chosen slices that reflect the variability your system will eventually see: slides from new hospitals, images from new scanners, fields from new regions, or scenes from different seasons and sensors. You don’t need huge datasets—just the right ones.
-
Long-tail challenge packs — rare phenotypes, unusual weather, staining artifacts, cloud edges, necrotic regions, or underrepresented demographics. These reveal brittleness and highlight the data you may need to collect next.
Together, these three elements provide a realistic, domain-tailored evaluation environment—something generic benchmarks cannot offer.
Use Benchmark Results as a Strategic Roadmap
For external FMs, the benchmark helps you decide whether to adopt a model, how much adaptation is required, and whether a hybrid strategy makes sense. For internal FMs, it highlights which failure modes require new data, which training changes actually matter, and where continued investment is or isn’t justified.
A benchmark is more than a score. It’s a decision tool—a way to transform uncertainty into a clear development and adoption strategy.
If you'd like help designing a tailored benchmark for proprietary images—or reviewing vendor FM claims—I’d be happy to share what I’ve seen across domains.
Just hit REPLY to let me know you’re interested.
- Heather
|
|
 |
|
Vision AI that bridges research and reality
— delivering where it matters
|
|
|
|
|
|
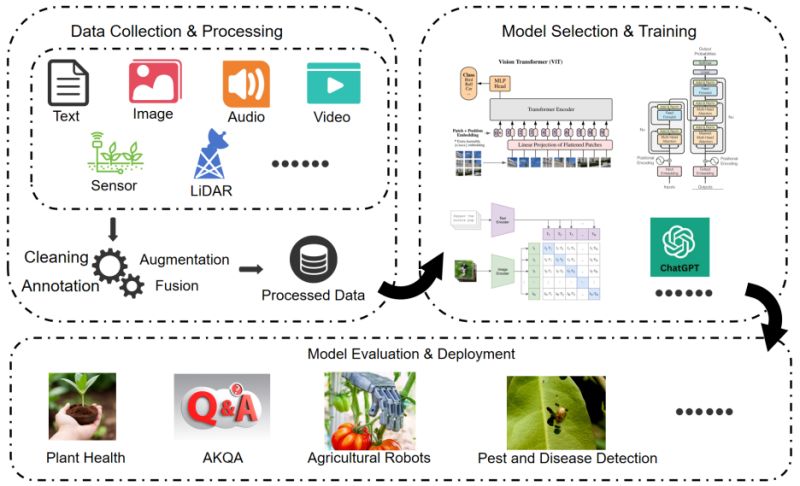 |
Research: Foundation Models for Agriculture
Foundation Models in Agriculture: A Comprehensive Review
As foundation models transform nearly every domain of AI, agriculture faces a unique set of opportunities and challenges. A new comprehensive review published in Agriculture synthesizes where Agricultural Foundation Models (AFMs) stand today and charts the path forward.
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬:
Traditional agricultural ML models rely heavily on large labeled datasets, require specialized expertise, and lack generalizability across tasks and environments. With a growing global population and accelerating climate change, agriculture needs intelligent decision support systems that can adapt efficiently to diverse contexts—exactly what foundation models promise.
𝐊𝐞𝐲 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬 𝐟𝐫𝐨𝐦 𝐭𝐡𝐞 𝐫𝐞𝐯𝐢𝐞𝐰:
The paper systematically examines 84 publications from 2019-2025, covering:
- 𝐀𝐅𝐌 𝐝𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲: Language models (like AgriBERT), vision models, and multimodal systems applied across crop classification, pest detection, and image segmentation
- 𝐔𝐬𝐞 𝐜𝐚𝐬𝐞𝐬: Agricultural knowledge Q&A, image and video analysis, decision support systems, and robotics
- 𝐔𝐧𝐢𝐪𝐮𝐞 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞𝐬: Agricultural data heterogeneity, temporal shifts in field conditions, asynchronous data streams (15-300ms latency between sensors), and deployment constraints for smallholder farms
𝐅𝐮𝐭𝐮𝐫𝐞 𝐝𝐢𝐫𝐞𝐜𝐭𝐢𝐨𝐧𝐬:
- Expanding beyond text and images to video analytics for real-time crop monitoring
- Integrating AFMs across the entire agricultural and food supply chain
- Developing "Model-as-a-Service" platforms with accessible interfaces for smallholder farmers
- Addressing the temporal relevance challenge—crop data becomes outdated as environmental conditions change
𝐓𝐡𝐞 𝐛𝐨𝐭𝐭𝐨𝐦 𝐥𝐢𝐧𝐞:
AFMs aren't just about applying existing foundation models to agriculture—they require rethinking model design for agricultural data characteristics, deployment contexts, and the unique temporal dynamics of biological systems. This review provides essential background for researchers entering the field and identifies critical gaps for advancing the technology.
|
|
|
|
|
|
 |
Insights: Clinical Validation
Clinical Validation Isn't a One-Time Event
A model that’s safe today might be risky tomorrow. Validation doesn’t end at deployment—it begins.
You’ve validated your pathology model on a held-out dataset.
It performs well. You publish the paper.
But six months later, real-world data looks different.
𝐈𝐧 𝐜𝐥𝐢𝐧𝐢𝐜𝐚𝐥 𝐬𝐞𝐭𝐭𝐢𝐧𝐠𝐬, 𝐝𝐫𝐢𝐟𝐭 𝐢𝐬𝐧’𝐭 𝐚 𝐭𝐡𝐞𝐨𝐫𝐲—𝐢𝐭’𝐬 𝐚 𝐠𝐢𝐯𝐞𝐧.
Scanners change. Protocols evolve. Populations shift. Slide quality, staining intensity, or even section thickness can vary across labs.
And models quietly lose accuracy—like a microscope slowly slipping out of focus.
🧪 Example: A breast cancer model trained on scanner A showed 92% sensitivity. After switching to scanner B across hospital sites, that dropped to 74%—but no one noticed for weeks.
𝐑𝐞𝐚𝐥‑𝐰𝐨𝐫𝐥𝐝 𝐯𝐚𝐥𝐢𝐝𝐚𝐭𝐢𝐨𝐧 𝐢𝐬 𝐨𝐧𝐠𝐨𝐢𝐧𝐠.
Static validation protects neither patients nor reputations.
You need post-deployment monitoring, QA workflows, and performance thresholds tied to real clinical risk.
𝐒𝐨 𝐰𝐡𝐚𝐭? A one-time validation gives a snapshot in time. Without ongoing validation, small drifts can snowball into missed diagnoses, unnecessary interventions, or trial delays—costing time, money, and trust.
𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲: A model is like a microscope—it needs calibration, not just installation.
💡 Developer tip: Implement drift detection and performance dashboards before clinical rollout. Your model’s first failure shouldn’t be spotted by a clinician.
📣 What’s a model drift issue you’ve caught—or missed—in the real world?
Leave a comment |
|
|
|
|
|
 |
Research: VLM for Agriculture
AgriGPT-VL: Agricultural Vision-Language Understanding Suite
Despite rapid progress in multimodal AI, agricultural applications face three fundamental constraints: lack of domain-tailored models, scarce high-quality vision-language datasets, and inadequate evaluation frameworks. Bo Yang et al. address all three simultaneously with AgriGPT-VL Suite.
𝐓𝐡𝐞 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞:
Building effective agricultural VLMs requires massive amounts of paired image-text data with domain expertise. Previous work either synthesized small datasets from vision-only data or relied on limited manual curation. Neither approach scales to the millions of examples needed for robust multimodal reasoning.
𝐓𝐡𝐞 𝐬𝐨𝐥𝐮𝐭𝐢𝐨𝐧—𝐀𝐠𝐫𝐢𝐆𝐏𝐓-𝐕𝐋 𝐒𝐮𝐢𝐭𝐞:
𝟏. 𝐀𝐠𝐫𝐢-𝟑𝐌-𝐕𝐋 𝐃𝐚𝐭𝐚𝐬𝐞𝐭 (largest agricultural VL corpus to date):
- 1M image-caption pairs
- 2M image-grounded VQA pairs
- 50K expert-level VQA instances
- 15K GRPO reinforcement learning samples
Generated by a scalable multi-agent system that combines caption generation, instruction synthesis, multi-agent refinement, and factual filtering—creating a reusable blueprint for scientific domain datasets.
𝟐. 𝐀𝐠𝐫𝐢𝐆𝐏𝐓-𝐕𝐋 𝐌𝐨𝐝𝐞𝐥:
Progressive curriculum training starting:
- Stage 1: Text-only domain grounding to consolidate agricultural knowledge
- Stage 2: Multimodal shallow/deep alignment on synthesized supervision
- Stage 3: GRPO refinement for enhanced reasoning
This approach achieves strong multimodal capabilities while preserving text-only performance—addressing a common failure mode where vision-language training degrades language-only abilities.
𝟑. 𝐀𝐠𝐫𝐢𝐁𝐞𝐧𝐜𝐡-𝐕𝐋-𝟒𝐊:
Comprehensive evaluation with 2,018 open-ended VQA and 1,858 single-choice questions (two per image for cross-validation). Covers recognition, symptom analysis, management recommendations, and multi-step reasoning. Strictly de-duplicated from training data and human-reviewed.
𝐊𝐞𝐲 𝐫𝐞𝐬𝐮𝐥𝐭𝐬:
AgriGPT-VL surpasses most flagship models on agricultural tasks. The multi-agent data generator provides a scalable, transferable approach for building domain-specific VL datasets—potentially applicable beyond agriculture to other scientific domains lacking paired vision-language data.
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬:
This represents a step-change in scale and rigor for agricultural AI: 3M+ training samples (vs. 70K in AgroGPT), comprehensive curriculum training (vs. single-stage tuning), and robust evaluation with 4K diverse test samples. The work demonstrates that with proper infrastructure, specialized domain models can compete with general-purpose systems.
|
|
|
|
|
|
 |
Insights: Trust
The Human Element
Trust doesn’t come from numbers. It comes from knowing what the model sees—and why.
𝐖𝐡𝐲 𝐏𝐚𝐭𝐡𝐨𝐥𝐨𝐠𝐢𝐬𝐭𝐬 𝐒𝐭𝐢𝐥𝐥 𝐃𝐨𝐧’𝐭 𝐓𝐫𝐮𝐬𝐭 𝐀𝐈 (𝐀𝐧𝐝 𝐖𝐡𝐲 𝐓𝐡𝐚𝐭’𝐬 𝐎𝐤𝐚𝐲)
AUROCs don’t build trust. Understanding does.
It’s earned through transparency, reliability, and communication.
Pathologists aren’t just “users.” They’re experts in a high-stakes domain.
They need to understand why a model flagged a region, not just what it predicted. The best AI tools behave more like a second set of eyes than a second opinion.
📍 Example: A model that flags tumor regions without clarifying why—or how confident it is—can feel more like a liability than a help. Even accurate black boxes get ignored. A model that shows saliency, confidence, or case comparisons invites interpretation—like a resident explaining their reasoning to a senior pathologist.
𝐓𝐫𝐮𝐬𝐭 𝐢𝐬 𝐜𝐥𝐢𝐧𝐢𝐜𝐚𝐥 𝐢𝐧𝐟𝐫𝐚𝐬𝐭𝐫𝐮𝐜𝐭𝐮𝐫𝐞.
Trust looks different for a second-opinion tool vs. one making trial enrollment decisions.
It takes time to build and seconds to lose.
AI that’s rigid, opaque, or ignores clinical judgment erodes trust—and adoption.
𝐒𝐨 𝐰𝐡𝐚𝐭?
Tools that ignore clinical expertise don’t just get sidelined—they lose trust, waste time, and stall progress.
𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲:
𝐀𝐈 𝐬𝐡𝐨𝐮𝐥𝐝 𝐬𝐮𝐩𝐩𝐨𝐫𝐭—𝐧𝐨𝐭 𝐬𝐮𝐩𝐩𝐥𝐚𝐧𝐭—𝐜𝐥𝐢𝐧𝐢𝐜𝐚𝐥 𝐣𝐮𝐝𝐠𝐦𝐞𝐧𝐭.
💬 What’s one thing a model could do to earn your trust in the lab?
Leave a comment |
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Pixel Clarity Call - A free 30-minute conversation to cut through the noise and see where your vision AI project really stands. We’ll pinpoint vulnerabilities, clarify your biggest challenges, and decide if an assessment or diagnostic could save you time, money, and credibility.
Book now |
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States |
|
|
|
|
