 |
Research: Hyperspectral Foundation Model
HyperFree: A Channel-adaptive and Tuning-free Foundation Model for Hyperspectral Remote Sensing Imagery
tWhat if an AI could analyze any hyperspectral image - from 46 to 274 spectral channels - without requiring image-by-image tuning? Even better, what if it could identify multiple objects of the same class with just a single prompt?
Jingtao Li et al. introduced HyperFree at CVPR 2025 - the first channel-adaptive, tuning-free foundation model for hyperspectral remote sensing that achieves comparable results to specialized models using just one prompt versus their five training shots.
𝐓𝐡𝐞 𝐡𝐲𝐩𝐞𝐫𝐬𝐩𝐞𝐜𝐭𝐫𝐚𝐥 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞: Hyperspectral imagery
captures hundreds of spectral channels spanning 400-2500nm, providing incredibly detailed Earth observation data. However, existing foundation models face a major bottleneck - they require expensive fine-tuning for each new dataset due to varying channel numbers across different sensors. This makes deployment costly and time-consuming, especially problematic given the high acquisition costs of hyperspectral data.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
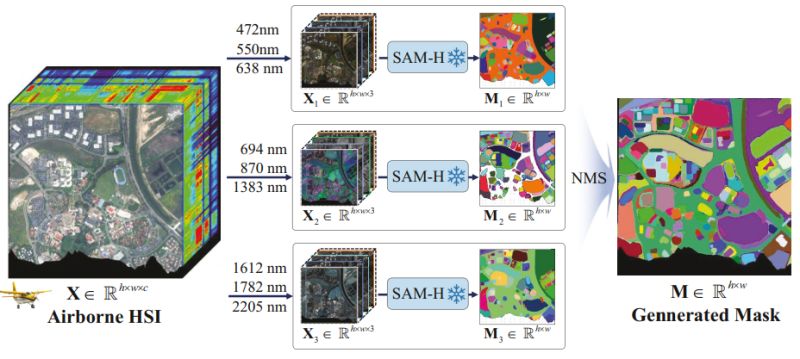
∙ 𝐋𝐞𝐚𝐫𝐧𝐚𝐛𝐥𝐞 𝐰𝐚𝐯𝐞𝐥𝐞𝐧𝐠𝐭𝐡 𝐝𝐢𝐜𝐭𝐢𝐨𝐧𝐚𝐫𝐲: Dynamic embedding generation spanning full spectrum (400-2500nm) at 10nm intervals, allowing processing of any hyperspectral sensor
∙
𝐏𝐫𝐨𝐦𝐩𝐭-𝐦𝐚𝐬𝐤-𝐟𝐞𝐚𝐭𝐮𝐫𝐞 𝐢𝐧𝐭𝐞𝐫𝐚𝐜𝐭𝐢𝐨𝐧: Novel approach treating feature distance as semantic similarity to generate multiple masks from a single prompt
∙ 𝐇𝐲𝐩𝐞𝐫-𝐒𝐞𝐠 𝐝𝐚𝐭𝐚 𝐞𝐧𝐠𝐢𝐧𝐞: Automated generation of 50k high-resolution hyperspectral images with 15 million segmentation masks using Segment Anything
∙ 𝐓𝐮𝐧𝐢𝐧𝐠-𝐟𝐫𝐞𝐞 𝐚𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞: Direct processing of unseen datasets across five tasks without model
modification
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬: HyperFree achieved state-of-the-art performance on 11 datasets across classification, target detection, anomaly detection, and change detection tasks - all in a tuning-free manner. In some cases, it even outperformed specialized models that were specifically trained on each dataset. This breakthrough makes hyperspectral AI more practical and accessible, reducing the computational burden and expertise required for deployment.
The work addresses a fundamental scalability challenge in Earth observation AI, potentially accelerating adoption of hyperspectral analysis across environmental monitoring, precision agriculture, and defense applications.
|
|
|
|
|
|
 |
Blog: Drug Development
Advanced AI Unlocks Precision Patient Stratification for Drug Development
The future of drug development is being rewritten by AI - and it's happening faster than most realize.
After diving deep into how advanced AI algorithms are transforming patient stratification in pharma, I'm convinced we're at a true inflection point. The numbers tell the story:
🔬 𝟭𝟬-𝟭𝟯% 𝗿𝗲𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗶𝗻 𝗱𝗶𝗮𝗴𝗻𝗼𝘀𝘁𝗶𝗰 𝗰𝗼𝘀𝘁𝘀
⏱️ 𝗧𝗿𝗲𝗮𝘁𝗺𝗲𝗻𝘁
𝗶𝗻𝗶𝘁𝗶𝗮𝘁𝗶𝗼𝗻 𝘁𝗶𝗺𝗲: 𝟭𝟮 𝗱𝗮𝘆𝘀 → <𝟭 𝗱𝗮𝘆
💰 𝗠𝗶𝗹𝗹𝗶𝗼𝗻𝘀 𝗶𝗻 𝘀𝗮𝘃𝗶𝗻𝗴𝘀 𝗽𝗲𝗿 𝘁𝗿𝗶𝗮𝗹
📈 𝗠𝗲𝗮𝘀𝘂𝗿𝗮𝗯𝗹𝘆 𝗵𝗶𝗴𝗵𝗲𝗿 𝘁𝗿𝗶𝗮𝗹 𝘀𝘂𝗰𝗰𝗲𝘀𝘀 𝗿𝗮𝘁𝗲𝘀
But here's what's really striking: AI isn't just improving existing processes—it's discovering entirely new biomarkers that human experts never knew existed. Paige's Virchow2
foundation model is already outperforming human pathologists across multiple institutions. Self-supervised models like CHIEF are enabling breakthrough applications with just hundreds of labeled cases instead of thousands.
The multimodal integration is where things get particularly exciting. When AI combines histopathology images with genomic and clinical data, we're seeing performance that completely outpaces traditional clinical risk scores.
𝗧𝗵𝗲 𝗿𝗲𝗮𝗹𝗶𝘁𝘆 𝗰𝗵𝗲𝗰𝗸: This isn't without challenges. Data privacy, algorithm bias, integration costs, and explainability requirements are real hurdles that companies need to navigate carefully.
𝗕𝗼𝘁𝘁𝗼𝗺 𝗹𝗶𝗻𝗲: The technology is advancing rapidly, and early adopters are seeing significant competitive advantages. The
question isn't whether AI will transform patient stratification—it's whether your organization will be leading or following this transformation.
What's your take? Are you seeing AI adoption accelerate in your pharma work?
|
|
|
|
|
|
 |
Research: Vision-Language Models
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
The most powerful vision-language models today remain proprietary, and even "open" models typically rely on synthetic data from closed systems like GPT-4V to achieve good performance. This creates a dependency problem for truly open AI development.
Matt Deitke et al. at the Allen Institute for AI introduced Molmo, a family of vision-language models that breaks this cycle by achieving state-of-the-art performance using only openly collected data and weights.
𝗧𝗵𝗲 𝗢𝗽𝗲𝗻𝗻𝗲𝘀𝘀 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲:
Most "open-weight" vision-language models still depend on synthetic data generated by
proprietary models, effectively distilling closed systems into seemingly open ones. This means the community lacks foundational knowledge about building high-performance VLMs from scratch without relying on proprietary dependencies.
𝗧𝗵𝗲 𝗔𝗽𝗽𝗿𝗼𝗮𝗰𝗵:
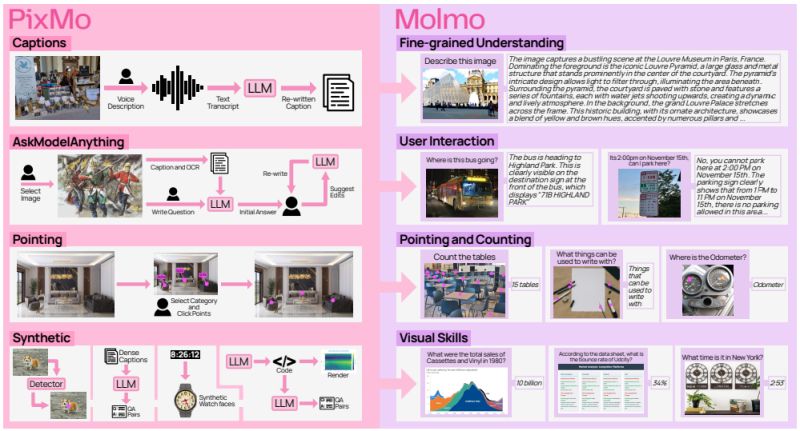
The key innovation is PixMo, a collection of carefully curated datasets totaling less than 1 million image-text pairs - three orders of magnitude smaller than typical training datasets:
• 𝗛𝗶𝗴𝗵𝗹𝘆 𝗱𝗲𝘁𝗮𝗶𝗹𝗲𝗱 𝗰𝗮𝗽𝘁𝗶𝗼𝗻𝘀: Collected through human speech-based descriptions lasting 60-90 seconds, capturing spatial relationships and detailed scene understanding
• 𝗙𝗿𝗲𝗲-𝗳𝗼𝗿𝗺 𝗤&𝗔:
Human-authored image question-answer pairs for real-world conversation capability
• 𝗜𝗻𝗻𝗼𝘃𝗮𝘁𝗶𝘃𝗲 𝟮𝗗 𝗽𝗼𝗶𝗻𝘁𝗶𝗻𝗴 𝗱𝗮𝘁𝗮: Enables models to respond to visual questions by pointing to specific image regions, not just text
𝗞𝗲𝘆 𝗥𝗲𝘀𝘂𝗹𝘁𝘀:
The 72B model achieves impressive performance across benchmarks and human evaluations:
• Outperforms Claude 3.5 Sonnet, Gemini 1.5 Pro, and Gemini 1.5 Flash
• Ranks second only to GPT-4o in comprehensive human preference evaluations
• Even the efficient 1B model nearly matches GPT-4V performance
• Uses 1,000x less training data than comparable approaches
𝗜𝗺𝗽𝗮𝗰𝘁:
This work demonstrates
that high-performance vision-language models can be built without dependencies on proprietary systems. The pointing capability opens new possibilities for AI agents that need to interact with physical or virtual environments - robots could query for object locations, or web agents could identify UI elements to interact with.
All model weights, datasets, and source code are publicly available, providing a foundation for truly open multimodal AI development and advancing our understanding of how to build capable VLMs from first principles.
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
Diagnostic -- Are you afraid your computer vision project will turn into an endless stream of failed experiments? What if you had a clear strategy for implementation? My Modeling Roadmap is a strategic plan outlining the components you’ll need to make your computer vision project a success using best practices for your type of imagery and bringing in cutting-edge research where needed.
Apply now
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
