Foundation Models: Promise, Pitfalls, and the Last-Mile Reality
Foundation models have become the default answer to almost every domain-specific AI problem. If you’re working in pathology, agriculture, earth observation, or any other data-rich scientific field, you’ve likely heard some version of the same pitch: pretrain once, adapt everywhere. The promise is compelling — faster development, fewer labels, and a shortcut around years of bespoke model building.
But after working with teams trying to deploy these models in real systems, a clearer picture emerges. Foundation models are powerful tools. They are also frequently misunderstood. And the gap between what they enable and what they replace is where many AI initiatives quietly stall.
The real question isn’t whether foundation models work. It’s where they work — and where their limitations surface.
The real promise
In visual domains, foundation models deliver genuine value in a few specific places.
They are exceptionally good at learning rich representations from large, messy, weakly labeled datasets. This matters in domains where annotation is expensive, slow, or requires expert time. Pretrained models can dramatically reduce the friction of early experimentation, allowing teams to prototype downstream tasks faster than traditional approaches.
Foundation models also lower the barrier to entry. Smaller teams can now start from a strong baseline instead of training everything from scratch. In some cases, a well-chosen pretrained model can outperform years of hand-engineered pipelines.
These are real advances. Ignoring them would be shortsighted.
Where the cracks appear
The problems begin when foundation models are treated as solutions rather than components.
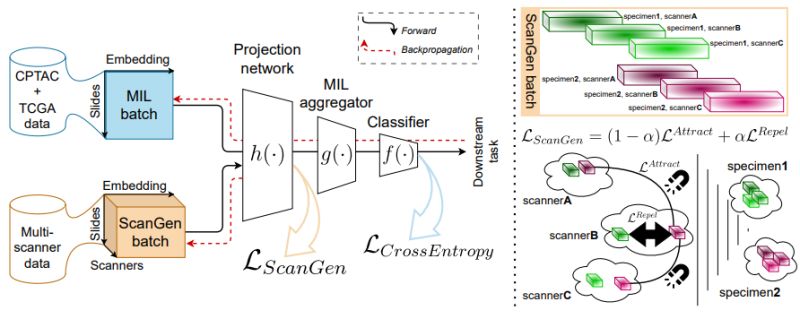
Most foundation models are trained on data that is convenient, not representative. In applied domains, that distinction matters more than architecture choice or parameter count. The moment a model encounters new scanners, sensors, geographies, protocols, or patient populations, performance can degrade in subtle but operationally meaningful ways.
Another common assumption is that scale substitutes for domain modeling. Larger models often mask data issues instead of resolving them. They can achieve impressive aggregate metrics while failing silently on long-tail cases — precisely the cases that matter most in safety-critical or high-stakes settings.
Then there is the cost of adaptation. While fine-tuning is often presented as relatively lightweight, in practice, it usually requires more planning than expected. Teams need to account for task-specific labeling, thoughtful validation design, ongoing monitoring, and integration into real workflows. What looks like a shortcut early on can introduce additional work later if these pieces aren’t anticipated upfront.
None of these are accidental failures. They are structural mismatches between how foundation models are marketed and how domain systems actually operate.
A reframing that helps
One mental shift makes these tradeoffs clearer: foundation models are not products.They are high-leverage components in a larger system that includes data, validation, and deployment decisions.
Impact depends far less on the model itself than on everything around it — task definition, evaluation strategy, data governance, and human-in-the-loop processes. A strong foundation model cannot compensate for unclear success criteria or poorly designed validation. In fact, it can delay those conversations by creating a false sense of progress.
Robustness is not an emergent property. It must be designed, tested, and maintained. Foundation models don’t remove that responsibility. They often make it more visible.
How leaders should evaluate foundation models
For decision-makers, the most important questions are not about model size or novelty. They are about behavior under constraint.
Where does this model reduce effort, and where does it introduce hidden costs? How does performance change under distribution shift? How much labeling is still required to reach acceptable reliability? What simpler baseline could achieve similar results with less complexity?
These questions don’t diminish the value of foundation models. They place them in context.
The bottom line
The promise of foundation models is not that they eliminate domain work. It’s that they accelerate the parts that were previously slow, while making the remaining challenges harder to ignore.
In applied AI, especially in scientific and medical domains, the last mile has not disappeared. It has simply moved.
Teams that succeed will be the ones that treat foundation models as starting points, not finish lines — and invest accordingly.
For teams navigating foundation models in applied settings, a short planning conversation early can prevent surprises later. My Pixel Clarity Call is designed to help you assess readiness, risks, and realistic paths to impact. Details here.
- Heather |