 |
Blog: Bias & Batch Effects
Your Model Might Be Misleading You: Bias and Batch Effects in Medical Imaging
𝗬𝗼𝘂𝗿 𝗺𝗼𝗱𝗲𝗹 𝗺𝗶𝗴𝗵𝘁 𝗯𝗲 𝗺𝗶𝘀𝗹𝗲𝗮𝗱𝗶𝗻𝗴 𝘆𝗼𝘂. And not because it's broken—because it learned the 𝘸𝘳𝘰𝘯𝘨 𝘵𝘩𝘪𝘯𝘨.
In medical imaging, models often appear to perform well… until they hit the real world. That's when shortcut learning and hidden biases—like site artifacts, scanner types, or demographic proxies—reveal themselves.
📉 A cancer model that learned the scanner type—𝘯𝘰𝘵 the
disease.
📍 A slide classifier that keyed in on lab-specific staining quirks.
🤯 A foundation model that could predict the hospital with 97% accuracy—𝘫𝘶𝘴𝘵 𝘧𝘳𝘰𝘮 𝘵𝘩𝘦 𝘪𝘮𝘢𝘨𝘦 𝘦𝘮𝘣𝘦𝘥𝘥𝘪𝘯𝘨𝘴.
These aren't rare bugs. They're 𝘤𝘰𝘮𝘮𝘰𝘯 𝘧𝘢𝘪𝘭𝘶𝘳𝘦 𝘮𝘰𝘥𝘦𝘴.
I published an article that walks through:
- Why models take shortcuts
- How to detect bias and batch effects early
- What actually helps (validation, sampling, and foundation models—done right)
- Why fairness in medical AI is a technical 𝘢𝘯𝘥 ethical imperative
It includes a 30-minute webinar replay packed
with visual examples and practical strategies.
|
|
|
|
|
|
 |
Research: Spatial Proteomics
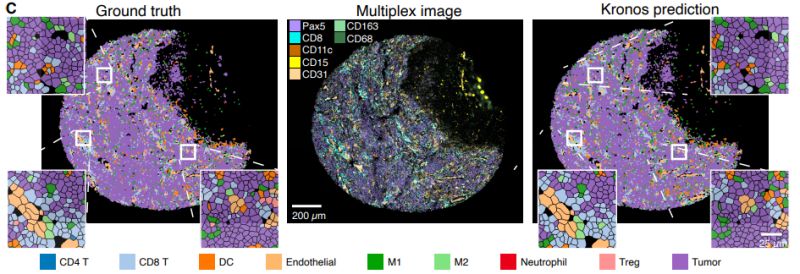
A Foundation Model for Spatial Proteomics
Understanding where proteins are located within tissues is crucial for cancer diagnosis, drug development, and precision medicine. But analyzing these complex spatial patterns has remained largely manual and inconsistent across laboratories.
Muhammad Shaban et al. developed KRONOS, a foundation model specifically designed for analyzing spatial proteomics data - imaging that maps protein expression at single-cell resolution within tissues.
𝗧𝗵𝗲 𝗖𝗵𝗮𝗹𝗹𝗲𝗻𝗴𝗲:
Current spatial proteomics analysis typically relies on cell segmentation followed by rule-based classification. While effective for well-defined cell types, this approach struggles
with complex tissue regions and treats each protein marker independently, potentially missing important spatial relationships.
𝗧𝗵𝗲 𝗔𝗽𝗽𝗿𝗼𝗮𝗰𝗵:
KRONOS was trained using self-supervised learning on 47 million image patches from 175 protein markers across 16 tissue types and 8 imaging platforms. The model uses a Vision Transformer architecture adapted for the variable number of protein channels in multiplex imaging.
𝗞𝗲𝘆 𝗧𝗲𝗰𝗵𝗻𝗶𝗰𝗮𝗹 𝗙𝗶𝗻𝗱𝗶𝗻𝗴𝘀:
The research identified several important architectural choices:
• 𝗠𝗮𝗿𝗸𝗲𝗿 𝗲𝗻𝗰𝗼𝗱𝗶𝗻𝗴
𝗶𝗺𝗽𝗿𝗼𝘃𝗲𝗺𝗲𝗻𝘁𝘀: Adding dedicated sinusoidal encoding for different protein markers yielded a large increase in balanced accuracy on Hodgkin lymphoma data
• 𝗧𝗼𝗸𝗲𝗻 𝘀𝗶𝘇𝗲 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻: Using smaller 4×4 pixel tokens improved accuracy compared to standard 16×16 tokens, though overlapping tokens with 50% overlap achieved similar performance
• 𝗘𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴 𝘀𝘁𝗿𝗮𝘁𝗲𝗴𝘆: Replacing image-level (CLS token) embeddings with marker-specific embeddings led to substantial performance
gains
𝗔𝗽𝗽𝗹𝗶𝗰𝗮𝘁𝗶𝗼𝗻𝘀 𝗗𝗲𝗺𝗼𝗻𝘀𝘁𝗿𝗮𝘁𝗲𝗱:
- Cell phenotyping without requiring cell segmentation
- Cross-dataset generalization across different imaging platforms
- Few-shot learning with limited labeled examples
- Patient stratification for treatment response prediction
- Tissue region classification and artifact detection
This work represents a step toward more automated and scalable analysis of spatial proteomics data, which could be valuable for biomarker discovery and understanding tissue architecture in disease.
Paper
Blog
Code
Model
|
|
|
|
|
|
 |
Insights: Hidden Data Biases
Self-Supervision Isn't Neutral in Earth Observation
Self-supervised learning is often described as more “objective”—free from the messiness of human labels.But in Earth observation, that objectivity is an illusion.
Even self-supervised pipelines are shaped by 𝗮 𝗰𝗮𝘀𝗰𝗮𝗱𝗲 𝗼𝗳 𝗵𝘂𝗺𝗮𝗻 𝗰𝗵𝗼𝗶𝗰𝗲𝘀.
Before a single pixel enters a foundation model, humans have already made decisions about:
🌍 𝗪𝗵𝗶𝗰𝗵 𝗿𝗲𝗴𝗶𝗼𝗻𝘀 to include—and which are left out
🍂 𝗪𝗵𝗶𝗰𝗵
𝘀𝗲𝗮𝘀𝗼𝗻𝘀 to sample (e.g., leaf-on vs leaf-off)
☁️ 𝗪𝗵𝗮𝘁 𝗺𝗮𝘀𝗸𝗶𝗻𝗴 𝘀𝘁𝗿𝗮𝘁𝗲𝗴𝘆 to apply for clouds, shadows, or snow
⏱ 𝗪𝗵𝗮𝘁 𝘁𝗶𝗺𝗲 𝗰𝗮𝗱𝗲𝗻𝗰𝗲 to use (daily, monthly, peak growing season)
These choices aren’t just technical—they embed 𝗶𝗺𝗽𝗹𝗶𝗰𝗶𝘁 𝗽𝗿𝗶𝗼𝗿𝗶𝘁𝗶𝗲𝘀:
Are we building a model that works globally, or for a handful of well-studied geographies?
Are we capturing biodiversity or agricultural productivity?
Are we learning texture, context, or just surface reflectance
patterns?
And those priorities affect what the model can learn—and what it will miss.
For example:
Training only on summer imagery? Your model may miss key transitions in crop growth or forest health.
Masking out all clouds? You might erase the very signals needed to predict floods or track storm damage.
🔍 These biases can show up later as “blind spots” in retrieval, segmentation, or classification—especially when applying models outside their original domain.
That’s why 𝘁𝗿𝗮𝗻𝘀𝗽𝗮𝗿𝗲𝗻𝘁 𝗿𝗲𝗽𝗼𝗿𝘁𝗶𝗻𝗴 𝗼𝗳 𝗽𝗿𝗲𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗱𝗮𝘁𝗮 𝗰𝗼𝗺𝗽𝗼𝘀𝗶𝘁𝗶𝗼𝗻
𝗮𝗻𝗱 𝘀𝗮𝗺𝗽𝗹𝗶𝗻𝗴 𝘀𝘁𝗿𝗮𝘁𝗲𝗴𝗶𝗲𝘀 𝗶𝘀 𝗲𝘀𝘀𝗲𝗻𝘁𝗶𝗮𝗹, even for models marketed as “unsupervised” or “foundation.”
📌 Just because you didn't provide labels doesn’t mean you didn’t provide structure.
𝗘𝘃𝗲𝗿𝘆 ‘𝘂𝗻𝗹𝗮𝗯𝗲𝗹𝗲𝗱’ 𝗱𝗮𝘁𝗮𝘀𝗲𝘁 𝗰𝗮𝗿𝗿𝗶𝗲𝘀 𝗵𝗶𝗱𝗱𝗲𝗻 𝗯𝗶𝗮𝘀𝗲𝘀.
👇 𝗛𝗮𝘃𝗲 𝘆𝗼𝘂
𝗲𝗻𝗰𝗼𝘂𝗻𝘁𝗲𝗿𝗲𝗱 𝗵𝗶𝗱𝗱𝗲𝗻 𝗯𝗶𝗮𝘀𝗲𝘀 𝗶𝗻 𝘀𝗼-𝗰𝗮𝗹𝗹𝗲𝗱 “𝘂𝗻𝗹𝗮𝗯𝗲𝗹𝗲𝗱” 𝗘𝗢 𝗱𝗮𝘁𝗮?𝗪𝗵𝗮𝘁 𝗮𝗽𝗽𝗿𝗼𝗮𝗰𝗵𝗲𝘀 𝗵𝗮𝘃𝗲 𝗵𝗲𝗹𝗽𝗲𝗱 𝘆𝗼𝘂 𝘀𝘂𝗿𝗳𝗮𝗰𝗲 𝗼𝗿 𝗺𝗶𝘁𝗶𝗴𝗮𝘁𝗲 𝘁𝗵𝗲𝗺?
Leave a comment
|
|
|
|
|
|
 |
Research: Remote Sensing Foundation Model
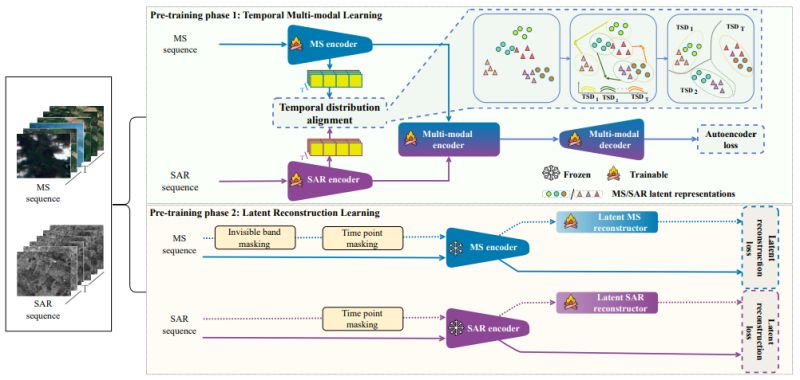
RobSense: A Robust Multi-modal Foundation Model for Remote Sensing with Static, Temporal, and Incomplete Data Adaptability
What happens when satellite data is incomplete, with missing spectral bands or temporal gaps? Current remote sensing AI models often struggle significantly. But what if an AI could still perform reliably even when critical data is missing?
Minh Kha Do et al. introduced RobSense at CVPR 2025 - a foundation model that thrives on incomplete data while supporting diverse input types from static images to temporal sequences across multiple sensor modalities.
𝐓𝐡𝐞 𝐦𝐢𝐬𝐬𝐢𝐧𝐠 𝐝𝐚𝐭𝐚 𝐜𝐡𝐚𝐥𝐥𝐞𝐧𝐠𝐞: Real-world satellite data is often incomplete due to sensor degradation,
extreme weather, or varying acquisition schedules. Most foundation models require fixed numbers of spectral bands and complete temporal sequences, making them brittle when deployed in operational settings where data gaps are common.
𝐊𝐞𝐲 𝐢𝐧𝐧𝐨𝐯𝐚𝐭𝐢𝐨𝐧𝐬:
∙ 𝐅𝐮𝐥𝐥 𝐢𝐧𝐩𝐮𝐭 𝐯𝐞𝐫𝐬𝐚𝐭𝐢𝐥𝐢𝐭𝐲: First model to support all four input types - static/temporal and uni-modal/multi-modal data
∙ 𝐓𝐞𝐦𝐩𝐨𝐫𝐚𝐥 𝐝𝐢𝐬𝐭𝐫𝐢𝐛𝐮𝐭𝐢𝐨𝐧 𝐚𝐥𝐢𝐠𝐧𝐦𝐞𝐧𝐭: Novel approach using multivariate KL divergence to
align multi-spectral and SAR data across time
∙ 𝐋𝐚𝐭𝐞𝐧𝐭 𝐫𝐞𝐜𝐨𝐧𝐬𝐭𝐫𝐮𝐜𝐭𝐨𝐫𝐬: Dedicated modules that recover rich representations from incomplete inputs
∙ 𝐓𝐰𝐨-𝐩𝐡𝐚𝐬𝐞 𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠: Temporal multi-modal learning followed by specialized incomplete data handling
𝐖𝐡𝐲 𝐭𝐡𝐢𝐬 𝐦𝐚𝐭𝐭𝐞𝐫𝐬: RobSense consistently outperformed state-of-the-art models across segmentation, classification, and change detection tasks. More importantly, performance gaps widened as missing data increased - achieving 46.36% mIoU on complete datasets and maintaining strong performance even with 70% missing
data. This robustness is crucial for operational Earth observation systems where perfect data coverage is unrealistic.
The work addresses a fundamental deployment challenge in remote sensing AI, moving beyond laboratory conditions to handle the messy realities of real-world satellite data.
When have missing bands or temporal gaps caused headaches in your EO projects? How did you handle it?
|
|
|
|
|
|
 |
Insights: Pathology AI
From Research Code to Clinical Tool
𝐸𝑣𝑒𝑛 𝑡ℎ𝑒 𝑠𝑚𝑎𝑟𝑡𝑒𝑠𝑡 𝑚𝑜𝑑𝑒𝑙 𝑤𝑖𝑙𝑙 𝑓𝑎𝑖𝑙—𝑖𝑓 𝑖𝑡 𝑓𝑎𝑖𝑙𝑠 𝑡ℎ𝑒 𝑝𝑒𝑜𝑝𝑙𝑒 𝑤ℎ𝑜 𝑛𝑒𝑒𝑑 𝑡𝑜 𝑢𝑠𝑒 𝑖𝑡.
In research, a successful model gets a plot and a paper—but in the clinic, it must help a pathologist make a real decision.
𝐂𝐥𝐢𝐧𝐢𝐜𝐚𝐥
𝐭𝐨𝐨𝐥𝐬 𝐧𝐞𝐞𝐝 𝐦𝐨𝐫𝐞 𝐭𝐡𝐚𝐧 𝐦𝐨𝐝𝐞𝐥 𝐩𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐧𝐜𝐞.
They require:
- Seamless workflow integration
- Intuitive, user-centered interfaces
- Interpretable, actionable outputs
- Traceability and audit trails
🧪 Example: A prostate grading tool with a confusing interface might get ignored—even if it has high AUROC. But a simpler model with seamless LIS integration and heatmaps aligned to H&E features may be used daily.
That contrast isn’t about performance—it’s about usability. A model that’s easy to adopt wins, even if it’s technically simpler.
Even a high-performing model will be sidelined if it slows pathologists down, adds friction, or creates more questions than
answers.
Multiply that friction across a hospital, and that AI turns from innovation into inefficiency.
𝐒𝐨 𝐰𝐡𝐚𝐭?
A model that lives on a server but never sees use at the microscope is wasted effort. Clinical impact comes not just from performance—but from usability that enables adoption.
𝐓𝐚𝐤𝐞𝐚𝐰𝐚𝐲: Usability isn’t a nice-to-have—it’s the difference between real-world adoption and being shelved.
💡 Developer tip: Before shipping a model, sit with a pathologist and watch them try to use it. If they hesitate, struggle, or need instructions—it’s not ready.
🤝 Better yet: co-design with pathologists. You'll spot usability issues before they become adoption barriers.
📣 Have you seen an AI tool succeed because of a design choice—or fail despite great performance? What stood out?
Leave a comment
|
|
|
|
|
|
Enjoy this newsletter? Here are more things you might find helpful:
1 Hour Strategy Session -- What if you could talk to an expert quickly? Are you facing a specific machine learning challenge? Do you have a pressing question? Schedule a 1 Hour Strategy Session now. Ask me anything about whatever challenges you’re facing. I’ll give you no-nonsense advice that you can put into action immediately.
Schedule now
|
|
|
Did someone forward this email to you, and you want to sign up for more? Subscribe to future emails
This email was sent to _t.e.s.t_@example.com. Want to change to a different address? Update subscription
Want to get off this list? Unsubscribe
My postal address: Pixel Scientia Labs, LLC, PO Box 98412, Raleigh, NC 27624, United States
|
|
|
|
|
